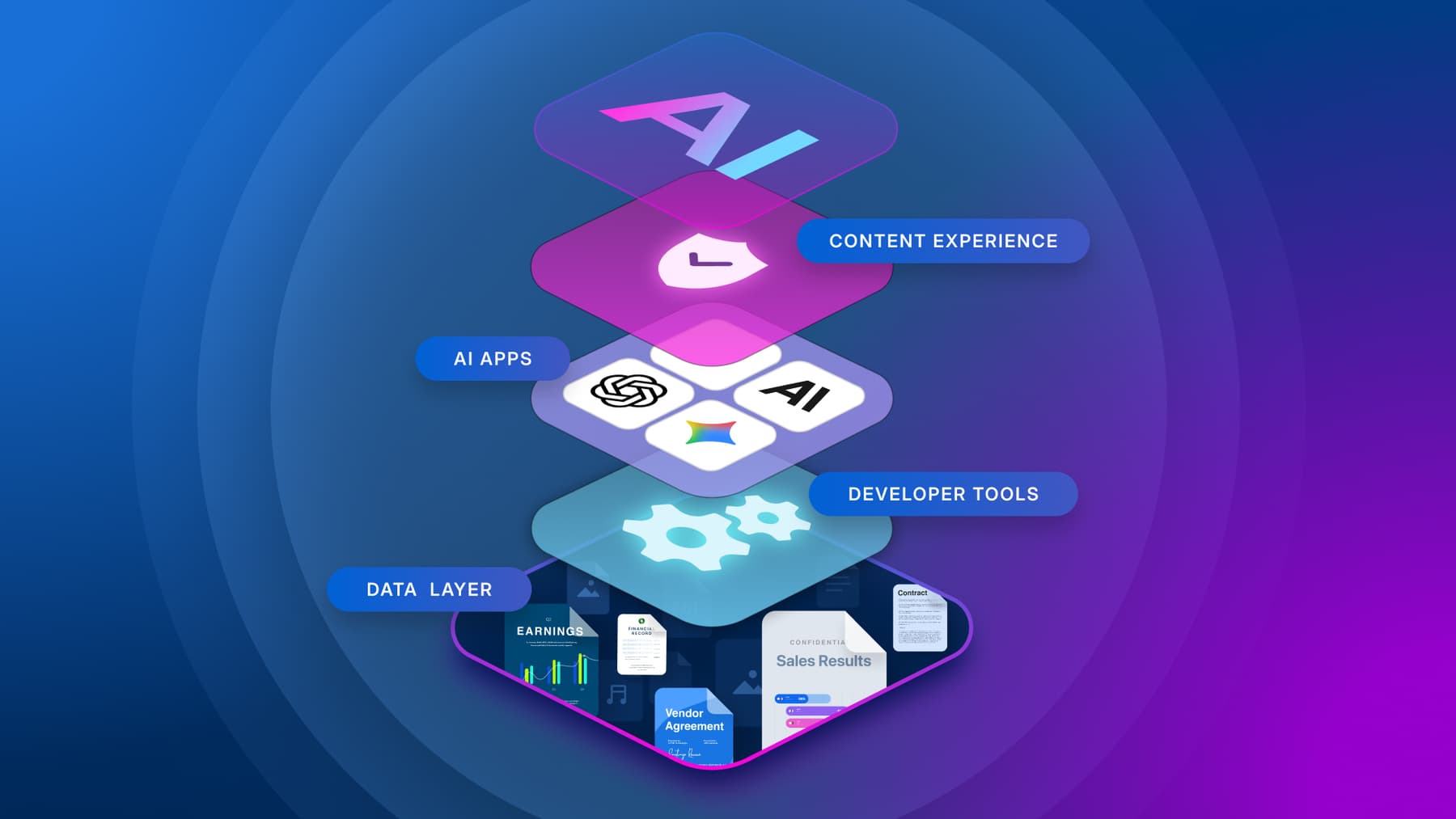
Centralizing unstructured data for AI is the process of organizing, enriching, governing, and curating documents, images, videos, scans, and other file-based content into a unified, governed layer that AI systems can access safely and effectively. For leaders, this work determines whether enterprise AI initiatives can move from experimentation to production.
The first step to centralizing content (also called unstructured data) for AI is to consolidate it from fragmented silos onto a single governed platform. This doesn’t necessarily mean moving all of your data into one place. With a unified visibility and governance layer that integrates with the tools your teams use to create and collaborate on content, AI systems can access the right content, under the right permissions, at the right time, regardless of where that content is created.
Box provides this layer through Intelligent Content Management that spans security, classification, tool integrations, AI capability, and workflow automation. With Box, you can also enrich your files with business metadata, apply sensitive data controls, and curate targeted datasets for specific AI workflows.
Read on to learn the risks of uncentralized unstructured data, the core barriers to AI readiness, the maturity stages organizations move through, and how platforms like Box support enterprise content governance and AI activation.
Key takeaways to prepare unstructured data for AI
- Unstructured data, or content, is the raw material many enterprise AI systems reason from
- AI projects can fail when unstructured data is fragmented, poorly indexed, duplicated, outdated, sensitive, or inaccessible to governed AI workflows
- AI data readiness requires both governance and quality: data must be authorized, classified, relevant, current, accurate, and safe to ingest
- Box helps enterprises manage, secure, govern, automate, and activate business content for AI with tools like Box AI, Box AI Studio, Box Agent, Box Shield, Box Governance, Box Automate, Box Hubs, Box Extract, Box Doc Gen, Box Sign, Box Apps, Box Platform APIs, and the Box MCP server
Why AI-ready unstructured data matters
When you think of AI, you think it can just work — but it doesn’t. There has to be a foundation. Garbage in, garbage out has never been more real: if AI is reading your information, it has to be quality information.
— Mike Carlino, Principal, AI & Data, Deloitte
AI systems are only as useful, safe, and trustworthy as the data they can access. When enterprise AI tools ingest noisy, stale, duplicated, or poorly governed content, they return lower-quality outputs, increase compute costs, and create security or compliance exposure. And sometimes they just don’t work.
The challenge of uncentralized unstructured content is getting more acute in the age of agentic AI. The Box State of AI Report 2026 found that 96% of organizations say AI agents need access to company-specific content.

Unstructured data preparation is now an operational prerequisite for AI at scale. It’s easy to select a model and deploy infrastructure. It’s harder to build a repeatable way to locate, classify, curate, and deliver the right content to the right AI workflow without putting sensitive information at risk.
In a time of sophisticated cybercrime and increasingly complex governance, AI data preparation is a critical subject for security, legal, and compliance teams. Done right, it reduces the risk that personally identifiable information, protected health information, confidential contracts, intellectual property, or regulated records will enter AI pipelines without authorization.
And on a productivity level, for knowledge workers, better AI data preparation improves the usefulness of AI-assisted search, summarization, workflow automation, content generation, and decision support. When AI is grounded in current, relevant, governed content, it becomes more reliable in day-to-day work.
As Box SVP and Global CIO Ravi Malick noted of companies furthest along with AI automation, “Every customer that we spoke with this year, without exception, emphasized that AI success didn’t start with AI. It actually started with decisions that they’d made years earlier about where their content lives, how it’s organized, and who has access to it.”
What does “AI-ready” unstructured data actually mean?
Unstructured data is information that doesn’t follow a fixed database schema. It’s all your content — the documents, files, and records that represent how your organization works and are essential to workflows.
Unstructured data includes files like:
- Documents
- PDFs
- Images
- Videos
- Audio files
- Medical scans
- Sensor streams
- Research files
- Contracts
- Chat and conversational records
- Presentations and spreadsheets stored as business content
Unlike structured data in rows and columns, these kinds of unstructured data require metadata, classification, content extraction, and governance controls before AI systems can use them reliably.
Why unstructured data creates unique AI risk
AI systems learn from, reason over, retrieve from, and generate outputs based on the data they can access. If that data includes sensitive records, proprietary intellectual property, regulated information, or personally identifiable information, weak governance can create risks beyond poor model performance.
Box Senior Director for Product Management Fernando Cerenza describes how rogue individual AI use becomes problematic for the enterprise: "People started to manually upload their content directly into the AI to get their question answered, and this created a lot of headaches for CIOs in particular, who now suddenly started seeing that IP, their contracts, their secret sauce being uploaded to all these different platforms."
The Box State of AI Report 2026 found that 49% of organizations have already had an AI-related data exposure incident in which an AI tool surfaced content a user shouldn’t have been able to access. As we move into AI automation and agents used across workflows, it’s even more important to lock down the use of AI tools within the organization and ensure that company content isn’t being used to train public models.
The risk landscape has two major dimensions:
- Governance risk: AI systems access or expose data that was never authorized for AI use
- Quality risk: AI systems reason from outdated, duplicated, irrelevant, or inaccurate data
Both dimensions matter equally. AI data readiness depends on both data governance and data quality.
Governance ensures that content has been vetted, classified, authorized, and controlled before it reaches an AI model, RAG pipeline, or agent. It focuses on questions like:
- Is this data allowed to be used for AI?
- Does it contain PII, PHI, confidential IP, or regulated content?
- Who approved its use?
- Can the organization prove lineage and access history?
Quality ensures that AI systems work from the right information. It focuses on questions like:
- Is this content current?
- Is it relevant to the use case?
- Is it duplicated or obsolete?
- Does it contain enough metadata for meaningful retrieval?
- Will it improve or degrade model outputs?
Governance without quality can leave AI systems using authorized but irrelevant data. Quality without governance can expose regulated, confidential, or legally protected content. A strong AI data preparation strategy addresses both.
Heather Ceylan, Chief Information Security Officer at Box, recently explained to the UK-based CyberWire podcast how “organizations have tolerated the unstructured content governance problem for a long time because when you’re talking about humans accessing that content, the blast radius was limited. But now, as we start to talk about agents accessing that content on such a large scale, that problem becomes much more critical to solve.”


What end-to-end AI data preparation involves
AI data preparation is the end-to-end process of making enterprise data accurate, relevant, accessible, and safe for AI pipelines. For unstructured data, this typically includes:
- Discovering where content exists
- Indexing metadata across storage systems
- Enriching files with business context
- Detecting sensitive or regulated information
- Removing or excluding irrelevant, duplicated, stale, or unauthorized content
- Curating datasets for training, fine-tuning, retrieval-augmented generation (RAG), inference, or agentic AI workflows
- Maintaining lineage and audit trails for compliance
This process isn’t a one-time preprocessing task. Enterprise content changes constantly, so AI data preparation must be continuous.
Common barriers to getting unstructured data ready for AI
Preparing unstructured data for AI is a compound problem. Several barriers can independently derail an AI initiative.
Fragmented data silos are the most obvious barrier. As Box CEO Aaron Levie said, “The way that we manage our information in most enterprises... tends to be highly fragmented across a wide variety of systems over a ten or twenty or thirty year period.”
As a result, enterprise data often lives across on-premises NAS arrays, cloud object stores, hybrid environments, collaboration platforms, and department-specific repositories. Without unified visibility, AI datasets are often incomplete, duplicated, biased toward accessible systems, or assembled manually.
But “This fragmentation isn’t just inconvenient,” Levie emphasizes. “It prevents AI adoption. Agents can’t automate what they can’t access, can’t optimize what they can’t understand, and can’t transform business if 90% of knowledge remains locked away."
Insufficient metadata limits classification. System metadata like file name, size, creation date, and last-accessed timestamp doesn’t reveal whether a document is relevant to a project, whether an image has been superseded, or whether a file contains regulated data.
“That level of intentionality about data structure,” says Box Chief Customer Officer Jon Herstein,“is really what separates organizations that are ready for AI and getting value from the unstructured content from those that aren’t.”
In a Box AI-First Podcast conversation, Herstein spoke with Robert Entin, CIO of the real-estate investment trust Vornado, on how important metadata is to the company’s AI efforts. Entin explained how Vornado put AI at the center of its digital strategy and introduced early use cases like automating rent billing and managing two million invoices. Applying metadata to unstructured data was key to those efforts. “The more metadata and more layers of metadata we can put against that unstructured data,” Entin says, “the more powerful it becomes.”
Incomplete AI data governance creates compliance and security exposure. AI governance requires sensitive data detection, provenance, and lineage tracking, auditable labeling, bias detection and mitigation, and human oversight mechanisms for AI-derived outputs.
Box’s State of the AI Report found that only 34% of surveyed companies had formal standards governing how agents access company data. "About three quarters of organizations today are saying that their current governance is slowing down their agent rollouts,” says Olivia Nottebohm, Box COO. “More than nine in ten say better governance over time will let them move even faster.”
Poor unstructured data quality creates data swamps. Duplicate files, abandoned project archives, outdated reference materials, and mislabeled records accumulate in large repositories and make it difficult to create clean AI-ready datasets.
Costly data movement becomes a major operational challenge. AI workflows are iterative, so data may need to be refreshed, retrained, re-indexed, or re-delivered many times. Repeatedly copying petabytes of data across environments can sharply increase storage and compute costs.
Traditional ETL doesn’t work for unstructured AI data
Extract, transform, load (ETL) workflows were built primarily for structured data moving into data warehouses on predictable schedules. AI workflows are different: they’re iterative, non-linear, and may require different datasets for training, fine-tuning, retrieval, inference, and agents.
For unstructured data, traditional ETL can be impractical because:
- File estates may span petabytes and billions of files
- File formats are heterogeneous
- Business context is often missing from system metadata
- Sensitive content may be embedded in documents and images
- Repeated data movement can increase cost and complexity
- AI datasets need continuous refresh, not one-time loading
The alternative is to classify, govern, and curate content before ingestion. This is where metadata comes in.
Metadata-first curation for AI datasets
"Most organizations classify a fraction of their content,” says Manoj Asnani, Box’s VP of Product Management. “But we can classify almost all their content, with a much deeper and nuanced understanding of that content based on its context."
Metadata is key to this effort. Metadata-first curation is an approach to AI data preparation that indexes and enriches data where it already lives before moving it. Instead of copying broad file collections into an AI platform and filtering downstream, organizations first identify exactly which files are relevant, safe, current, and authorized.
A metadata-first workflow typically looks like this:
- Build a unified index of content and metadata
- Add business-specific tags and classifications
- Detect sensitive or restricted content
- Query for files that match an AI use case
- Exclude irrelevant, stale, duplicated, or sensitive data
- Deliver only the curated dataset to the AI workflow
- Log lineage and governance details
This approach is especially important for unstructured data at enterprise scale, where bulk movement is expensive and broad ingestion increases both risk and noise. John Rhodes, Managing Director of Data Privacy and Technology Compliance at Insperity, says, “Our belief is that a piece of content that doesn't have metadata to it might as well be a dead piece of content."


Data noise and ROT data in AI pipelines
It’s also key to weed out the data that will just create noise for AI. Noisy unstructured data includes content that’s redundant, obsolete, trivial, stale, duplicated, irrelevant, or insufficiently labeled. This content, commonly known as ROT data (redundant, obsolete, and trivial data), is a common source of AI noise.
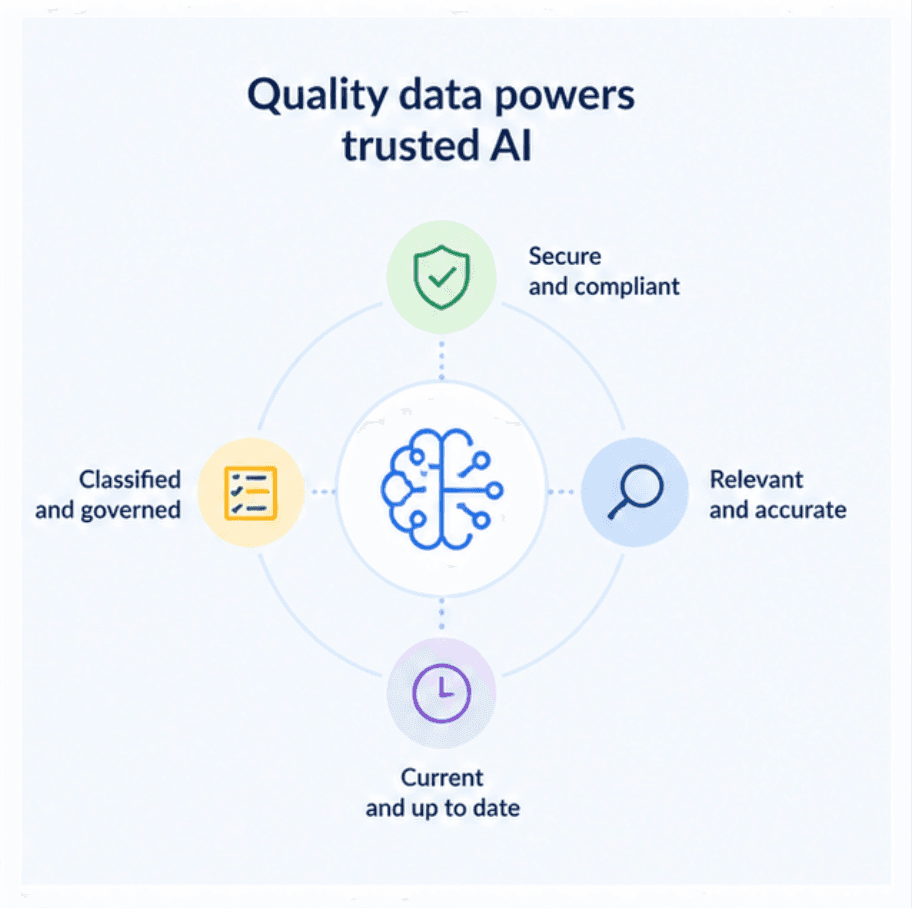
“ROT within the enterprise represents 40 to 50% of all information,” says Deloitte’s Carlino. “If unstructured information within the enterprise is 80% of all information, then you’re getting into a really large amount of information that has to be sifted out."
Data noise can:
- Reduce the signal-to-noise ratio in AI datasets
- Waste context window capacity in RAG and agentic AI systems
- Increase storage, transfer, and inference costs
- Cause AI systems to reason from outdated or contradictory content
- Increase the likelihood that sensitive or unauthorized content is included
AI-ready data programs should identify and exclude ROT data before it reaches AI pipelines. One of the most important things to do is to consistently archive content. Paradoxically, AI can also help with this effort. “I think another thing AI can really help with is archiving content that’s no longer relevant,” says Box CISO Ceylan. “You don’t want agents to go back and probably search a hundred years worth of content."
Sensitive data detection before AI ingestion
“AI has brought a new type of user to the enterprise: the agent,” says Asnani. “And just like any user, agents should go through security.”
In addition to eliminating ROT, it’s also critical to identify the information that requires protection before it enters AI systems and is put to use by agents. This type of sensitive data detection can include identifying (and blocking):
- Personally identifiable information (PII)
- Protected health information (PHI)
- Confidential contracts
- Intellectual property (IP)
- Regulated records
- Security-sensitive content
- Data matching custom keyword or regex patterns
The most effective control point is before ingestion. Blocking sensitive data at the pipeline boundary is more reliable than attempting post-ingestion remediation after the data has already reached a model, index, agent, or AI service.
“AI can actually help us classify that content,” Ceylan says, “not just based on keywords or regexes like historical DLP solutions have provided security teams in the past. AI can actually understand what the content is, how sensitive the content is, and it can proactively put those labels on the content for us."
Provenance, lineage, and audit trails for AI data
Because AI models and agents make decisions based on the data they ingest, establishing clear data provenance and lineage is far more than a compliance checkbox; it’s a fundamental security requirement to ensure those decisions are auditable, trustworthy, and safe.
Provenance describes where data came from and whether it’s trustworthy for a particular use. Lineage tracks the movement and transformation of data over time.
For AI data preparation, lineage should answer questions like:
- What data was ingested?
- Which source system did it come from?
- When was it ingested?
- Who authorized it?
- What governance policies were applied?
- Was any sensitive content excluded?
- Which AI workflow used the data?
Audit trails are essential for demonstrating compliance with requirements like GDPR, HIPAA, and intellectual property controls.
How to prepare unstructured data for AI in practice
Organizations can prepare unstructured data for AI by applying five practical tactics.
Build unified visibility across storage silos: AI teams can't govern or curate data they can't see. A unified metadata layer helps IT understand data growth, access patterns, file types, and staleness.
Move beyond ETL as the default model: AI workflows need metadata-first curation, governance, and selective movement rather than broad extraction and downstream filtering.
Deliver curated datasets instead of file dumps: AI systems perform better when they receive targeted datasets selected by business criteria like project code, content type, sensitivity status, owner, recency, and relevance.
Automate sensitive data exclusion: PII, PHI, confidential contracts, and proprietary research should be detected and blocked before reaching AI-accessible collections.
Invest in AI data management operations: IT teams need processes for cross-functional collaboration, data quality reporting, storage FinOps, ransomware risk reduction, workflow automation, and audit trails.
Box supports each of these steps. Organizations that consolidate content in Box before deploying AI have a structural advantage: the governance, classification, and access control work is already done, which means AI workflows can be built on a trusted content foundation rather than retrofitting governance after the fact.


Common pitfalls in unstructured data preparation for AI
While deploying AI models and infrastructure has become increasingly straightforward, organizations frequently stumble when preparing their unstructured content, falling into critical traps that compromise both the security and the quality of their AI initiatives. Here are the top pitfalls they encounter:
- Starting with ingestion instead of governance: Organizations that move data into AI pipelines before classifying and governing it create security and compliance exposure that’s difficult to remediate after the fact.
- Treating data preparation as a one-time task: Enterprise content changes constantly. AI data pipelines need continuous refresh, not a single preprocessing pass.
- Underestimating ROT data volume:Nearly half of enterprise data is redundant, obsolete, or trivial (ROT). AI systems that ingest ROT data waste compute, degrade output quality, and increase the risk of surfacing outdated information.
- Ignoring metadata: Files without business-context metadata are effectively invisible to AI classification and retrieval systems. Metadata enrichment is essential for AI-ready data programs.
- Fragmenting content governance across tools: When governance policies live in separate systems from the content itself, enforcement gaps are inevitable. The most reliable approach is a platform whose governance is built into the content layer.
- Fragmenting content governance across tools: When governance policies live in separate systems from the content itself, enforcement gaps are inevitable. The most reliable approach is a platform whose governance is built into the content layer.
How Box approaches unstructured data preparation for AI
In the simplest terms, Box operates as a governed content layer between enterprise files and the AI systems that use them. Box customers have classified more than 7 billion files using Box’s content classification capabilities — a scale that demonstrates the platform’s ability to handle enterprise-grade unstructured data governance.
AI is only as useful as the content it can access, and that content must be consolidated, secured, classified, and routed under enterprise controls before it ever reaches a model or agent. Rather than treating business files as an unmanaged data dump to be extracted and processed elsewhere, Box operates as a single Intelligent Content Management platform that powers the full content lifecycle: security, governance, compliance, workflow automation, and AI activation — all from one place.
Box AI lets people ask questions of documents, summarize large files, extract structured data from unstructured content, and surface insights — all within the permissions and access controls that are already established in Box. Box AI doesn’t train on customer content, meaning that proprietary contracts, regulated records, and sensitive business information remain contained. This is the governance-first model: AI operates inside the trust boundary of the content system, not outside it.
Box AI Studio lets admins build, configure, and deploy purpose-built AI agents for specific workflows, business processes, or departments. For AI data preparation, this matters because agents are only as effective as the content they can access, and AI Studio agents inherit Box’s existing classification, access controls, and governance by default. Admins can scope each agent’s knowledge to specific files or Box Hubs, so the agent operates over a deliberately curated content collection rather than the entire enterprise file estate.
Box Agent is Box’s AI agent that can search for relevant content, conduct deep research across large volumes of files, answer questions grounded in content, and generate new content based on what it finds. Built natively on the Box content layer, Box Agent uses permissions-aware retrieval, so it can be deployed against enterprise content without creating the access exposure that comes from connecting third-party agents to unstructured file stores.


Box Shield provides threat detection, classification-driven security controls, and ransomware protection for content stored in Box. For AI workflows specifically, Shield reduces the chance that an agent operating on Box content surfaces information to someone who shouldn’t have access to it (a risk that grows significantly as agentic AI systems operate across large, unstructured file sets).
Box Shield also supports content classification that can determine whether files are appropriate for internal use, external sharing, or AI ingestion, automating a control that would otherwise require manual review at scale. Box Governance allows organizations to tie sensitive data to retention policies — automatically identifying when content should be archived, held for legal review, or disposed of — so outdated or regulated content doesn’t persist in AI-accessible collections indefinitely. This is governance as an operational control, not just a compliance checkbox.


Box Automate supports workflow automation for AI data preparation and content operations. Teams can build multi-step workflows that route content for classification, review, approval, or downstream AI action, with the option to insert AI agents at specific decision points. This is important; manual curation bottlenecks are one of the most common reasons AI data preparation stalls in practice, and automating the routing logic allows governance steps to happen continuously without depending on IT to mediate every request.
Box Hubs supports curated knowledge experiences and maps directly to the curation principle of delivering precise, relevant content collections rather than broad file dumps. Hubs allow teams to organize selected content around a project, department, or business process and surface it to Box AI, so the AI is reasoning from a deliberately assembled, governed corpus, not an undifferentiated mass of files.
Box Hubs supports use cases ranging from loan document analysis to earnings call research to employee onboarding, where the quality and relevance of the underlying content collection determines the quality of AI-generated answers.
Vornado consolidated all unstructured data into Box and used Box Hubs to build a loan document AI assistant. According to CIO Robert Entin, the system answered every test question correctly, including the most difficult questions posed by the debt and acquisitions team.


Box Extract addresses the metadata enrichment challenge central to AI data readiness. It uses AI to automatically pull structured data out of unstructured documents — contracts, invoices, financial statements, shipping records — and attach that extracted metadata back to the files in Box. This turns content that would otherwise require manual inspection into queryable, classifiable, AI-ready data.
Box Sign and Box Doc Gen extend AI readiness into document workflows. Box Doc Gen generates documents from structured inputs and templates, reducing the manual effort in document creation while keeping outputs inside a governed content environment. Box Sign manages agreements and approvals within the same system, ensuring that executed documents are automatically filed, versioned, and accessible to downstream AI workflows without requiring manual transfer across tools.


Box Platform and the Box MCP server support integration with broader AI, data, and application ecosystems. The Box MCP server acts as a secure, compliant bridge that lets external AI agents and platforms, including Claude, Microsoft Copilot Studio, and others, access Box content without requiring custom integrations for each tool.
Because the MCP server inherits Box access controls, an agent operating through it can only surface content that the requesting person is already permitted to see. That security property matters: content governance established in Box travels with the content, even as it flows into external AI systems.
With the Box MCP server, we’ve essentially created a bridge, a secure and compliant bridge into all your Box content.
AI-ready content must be secure by design, governed throughout its lifecycle, and accessible to AI only under the right permissions and policies. Organizations that consolidate their content into Box before deploying AI have a structural advantage; the governance, classification, and access control work is already done, which means agents and AI workflows can be built on top of a trusted content foundation rather than scrambling to retrofit governance after the fact.


Frequently asked questions about unstructured data preparation for AI
What is unstructured data preparation for AI?
Unstructured data preparation for AI is the process of making documents, images, videos, scans, records, and other file-based content usable, relevant, and safe for AI systems. It includes discovery, metadata enrichment, classification, sensitive data detection, curation, lineage tracking, and governance.
Why is unstructured data harder to prepare than structured data?
Structured data usually follows a defined schema, which makes it easier to query, filter, and validate. Unstructured data lacks that built-in organization, so organizations must add metadata, inspect content, classify files, and apply governance controls before AI systems can use it effectively.
What are the biggest risks of using unprepared data in AI?
The biggest risks posed by unprepared data include poor AI outputs and unauthorized exposure of sensitive content. If AI systems ingest stale, duplicated, irrelevant, confidential, or regulated data, they may produce unreliable answers or create compliance, privacy, and intellectual property issues.
How does metadata-first curation work?
Metadata-first curation means indexing and enriching data where it already lives before moving it into an AI workflow. Instead of sending entire file shares to an AI platform, organizations use metadata and governance rules to select only the files that are relevant, current, authorized, and safe.
Why is traditional ETL often insufficient for unstructured AI data?
Traditional ETL was designed for structured data moving into data warehouses on predictable schedules. AI workflows are iterative, and unstructured data estates are often massive, heterogeneous, and governance-sensitive, making bulk extraction and downstream filtering expensive and risky.
How do you prevent sensitive data from entering AI pipelines?
The most reliable control point is before ingestion. Organizations should classify content for sensitivity, apply access and authorization checks; use automated detection for PII, PHI, confidential contracts, and regulated records; and block sensitive files at the pipeline boundary. Post-ingestion remediation (attempting to remove sensitive data after it has reached a model, index, or agent) is significantly less reliable.
What’s the difference between a RAG pipeline and a content management platform for AI?
A RAG (retrieval-augmented generation) pipeline retrieves relevant content at inference time to ground AI outputs. An Intelligent Content Management platform like Box governs, classifies, and curates the content that feeds those pipelines. The two are complementary: RAG determines how AI retrieves and uses content; the content platform determines whether that content is accurate, authorized, current, and safe to retrieve in the first place.
What is ROT data, and why does it matter for AI?
ROT data stands for redundant, obsolete, and trivial data. It matters because AI systems that ingest ROT data may waste compute, consume context window capacity, retrieve outdated information, and generate lower-quality outputs.
How does governance improve AI data readiness?
Governance improves AI data readiness by ensuring that content is authorized, classified, retained, audited, and protected before it reaches AI systems. It helps prevent sensitive data leakage, supports compliance, and creates a trustworthy record of what data was used and why.
What should organizations look for in a platform for AI-ready content management?
Organizations should look for a platform that provides unified visibility across content silos, automated metadata enrichment and classification, sensitive data detection before AI ingestion, policy-based curation and workflow automation, audit trails for compliance, and native AI capabilities that operate within established access controls. The platform should treat governance as a built-in property of content, not a post-processing step.
How does Box help organizations prepare content for AI?
Box supports AI-ready content through Intelligent Content Management , which helps organizations manage, secure, govern, automate, and activate business content. Tools like Box AI, Box AI Studio, Box Agents, Box Shield, Box Governance, Box Automate, Box Hubs, Box Extract, Box Sign, Box Doc Gen, Box Apps, Box Platform APIs, and the Box MCP server help teams apply AI to content under enterprise controls.
What’s the difference between AI data governance and AI data quality?
AI data governance focuses on whether data is authorized, protected, compliant, and auditable. AI data quality focuses on whether data is accurate, current, relevant, complete, and useful for the AI task.
Where should an organization start when preparing unstructured data for AI?
An organization should start by gaining visibility into where critical content resides, then classify and enrich it with useful metadata. The next steps are to apply governance controls, exclude sensitive or irrelevant content, curate targeted datasets, and automate refresh and audit workflows over time.
How does Box differ from traditional file storage for AI use cases?
Unlike traditional file storage, Box operates as an Intelligent Content Management platform that combines storage with built-in classification, governance, workflow automation, and AI activation. Content stored in Box is already subject to access controls, retention policies, and classification rules — meaning that AI systems operating on Box content inherit those governance properties automatically, rather than requiring a separate data preparation layer.