The fundamental challenge of enterprise AI isn’t capability — it’s reliability.
When I make a database query, I get the same answer every time. But when I query an LLM with the same prompt multiple times, I might get something completely different each time. Sometimes it’s a subtle variation. Sometimes it’s a hallucination that seems legitimate but is entirely fabricated.
How do you derive reliable, consistent outcomes from AI agents? At Box, our answer lies not in any one technique, but in the thoughtful orchestration of multiple approaches.
The challenge of getting accurate information in real-world scenarios
Let’s look at a typical scenario. If you want to find the payment information in a contract, you might use the AI prompt, “What are the payment terms?” Without a well-architected solution, you might get an answer of ”net 30 days,” but you still don’t know the exact date that payment is due. Beyond a page or two, the solution will struggle to connect the dots from one section to the next. And if you have a table in the document, you might get back a jumble of text that makes no sense at all.
When you’re processing thousands of invoices, contracts, or regulatory documents, these types of issues make automating processes difficult if not impossible. What you’re really after is a solution that can take your question, understand its deeper context, and deliver a precise, useful answer — then repeat that process, consistently and effectively, every single time.
Here’s how we do that with Box Extract.



The reliability pipeline
Our approach is to treat AI models as powerful components that need multiple levels of controls, data, tools, guardrails, and objectives:
Model orchestration
Box orchestrates the best available AI models through a platform-neutral and secure pipeline, applying temperature tuning, output constraints, and multi-model ensemble validation alongside agentic reasoning and prompt optimization to ensure every result is accurate, consistent, and deterministic.
Document preparation
A well-prepared document dramatically increases the accuracy of outcomes. So before any extraction takes place, we prepare the documents to be queried in order to maximize the LLM’s comprehension and minimize ambiguity. This includes Optical Character Recognition (OCR), layout and structural analysis, section identification, and context preservation.
Data extraction and semantic orchestration
This phase transforms raw content into structured outputs by first performing a deep layout understanding to identify structural elements like tables, forms, and headers. We then create semantic groups and apply relevant context based on layout type. Finally, we leverage multi-model ensembles and specialized field instructions to guide the underlying models to find and extract values, ensuring that we can drive accurate results from even complex document structures.
Output validation
We use various techniques to validate the output results. For example, with ensemble validation, we pose the same question to multiple LLMs and compare the results. In other cases, we calculate results based on information in the document. Such techniques provide signals whose validity we can then confirm with API calls to external systems.
Confidence scoring
Every extraction comes with a confidence level. This isn’t just model confidence. It’s our systematic assessment based on multiple factors:
- Model agreement (when using ensembles)
- Prompt specificity match
- Historical accuracy of similar extractions
- Document quality indicators
We provide confidence level by field to power various downstream workflows as needed.
Human-in-the-loop thresholds
Users can set specific confidence thresholds based on their risk tolerance, and extractions that don’t meet those thresholds will be diverted by Box Extract over for human review. These updates provide important signals back to our extraction agents for future jobs.

Evals: the foundation of accuracy
We help users build their evaluation datasets to enable our agents to learn and iterate. Say a Box customer provides 30 invoices and identifies 15 fields in those invoices that they need extracted. They then validate the correct answers for all those fields across all those documents. This becomes the initial eval set with ground truth. But we continue to add to this evolving knowledge base via signals collected from usage and any corrections made from HITL reviews.
What makes our ground truth approach particularly powerful is its continuous learning capability. When a user corrects an extraction — changing “Kelash Kumar” to “Norbert Raus” as the counterparty, for example — that correction feeds back into the ground truth and can be used to improve extract agents results.
And all these steps add up to a virtuous cycle:
- Initial ground truth allows the system to evaluate and configure agents
- Confidence scoring identifies uncertain extractions
- Human review corrects errors
- Corrections enhance ground truth
- System reoptimizes against expanded ground truth
So, over time, our system improves itself for each customer’s specific document types and extraction needs.
Next, we have an AI-powered optimization system that automatically generates and refines extraction prompts based on the evals. We’re finding the prompt formulations that maximize accuracy against known correct answers. The system runs simulations, performs testing, and reasons about different prompt variations by field. When extracting dates, for instance, it might learn that “find the first date after the header” works better than “find the invoice date” for a particular document type. These optimizations happen automatically and continually.
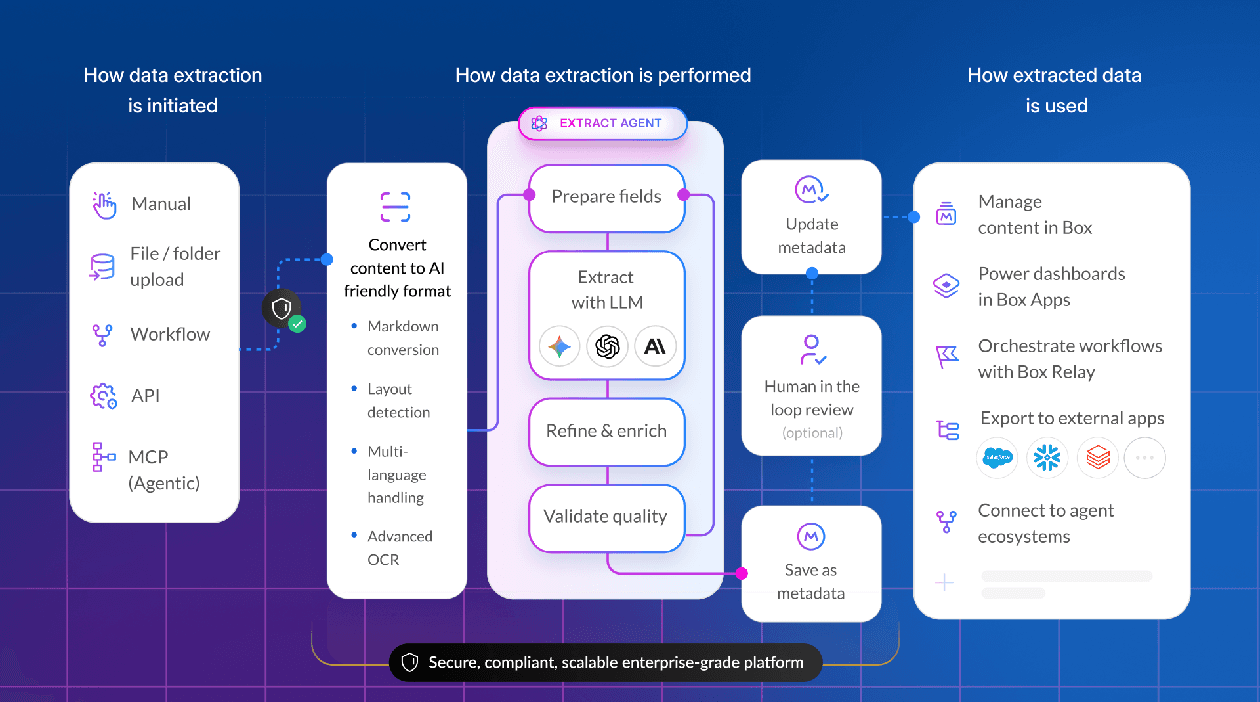

Practical implementation
Say you’re processing vendor contracts and need to extract payment terms, liability caps, and termination clauses. Here’s how our system handles it:
- Document ingestion
The contract is prepared and segmented, with relevant sections identified. - Prompt optimization
Based on your ground truth examples, the system has already optimized prompts for each field. For payment terms, it might have learned to look for specific keywords and numerical patterns. - Agentic extraction
Run extract agent with multiple results for each field and apply reasoning to identify fields that are codependent and iterate to build necessary context. - Confidence calculation
The system compares outputs. If all three models agree on “Net 30 payment terms,” confidence is high. If they disagree, confidence drops. - Threshold application
You’ve set a high confidence threshold for payment terms. Extractions below this threshold are routed to your team for review. - Human validation
Your team reviews flagged extractions and makes corrections which are fed back into the ground truth. - Continuous improvement
The system continually optimizes its prompts based on the expanded ground truth, thus improving future accuracy.
Over time this process could be further optimized with auto-verification logic based on defined rules that can feed into a review agent. In the end we’re looking to minimize human verification while providing accurate and trustworthy extraction results.
The accuracy automation curve
We measure our impact by pushing the accuracy automation curve. Imagine accuracy and automation as the X and Y axes on a graph. You want to be on the up and towards the right (higher accuracy and higher automation).

We’re optimizing the agent to maximize the level of automation, which is defined by how many extraction results need to be verified for a given accuracy threshold. This gives our customers the controls to align the extraction process to their specific workflow needs. Using agentic data extraction steps with continual learning, we’re optimizing agents to minimize the number of required verification while maintaining desired accuracy.
Beyond extraction
The techniques we’ve just described for Box Extract apply broadly to agentic AI systems. Any AI system that needs reliable outputs can benefit from:
- Layered confidence architectures that contain probabilistic nature rather than fighting
- Living eval sets that improve through usage
- Automated optimization that refines performance without manual tuning
- Flexible thresholds that let users fine-tune their speed/accuracy trade-off
- Feedback loops that turn corrections into improvements
We’re still in the early days of this approach. As models improve and baseline accuracy increases, we see several evolution paths:
- Specialized ground truth networks: Industries sharing anonymized ground truth to improve extraction accuracy across similar document types
- Adaptive confidence models: Systems that learn which document characteristics correlate with extraction errors and adjust confidence accordingly
- Hierarchical validation: Using increasingly powerful models to validate outputs from faster, lighter models — creating efficiency without sacrificing accuracy
- Domain-specific optimization: Automatic prompt engineering that understands industry terminology, document structures, and extraction requirements
The future path of enterprise AI
The path to enterprise AI adoption isn’t through perfect models — it’s through well-orchestrated systems. In launching Box Extract, we’re not just releasing a product. We’re proposing a philosophy: that the power of enterprise AI lies in trust. Trust in AI comes from building systems that learn, remember, and reliably deliver the certainty that enterprises need.
That’s the future we’re building at Box, one extraction at a time.

