The promise of AI agents is not that different from any other wave of enterprise technology: more speed, more leverage, more output from the same teams.
But the scale of that promise is much bigger, and it’s panning out. Box customers are deploying agents for drafting, research, approvals, support workflows, and operational tasks across the business.
In theory, multiple agents give enterprises a compounding advantage. If one agent saves time, five or ten should multiply that value.
Yet, many discover the opposite is true. As agent counts rise, outcomes don’t scale in a straight line. Agents have to repeat each other’s work. Different systems generate conflicting outputs. Governance teams scramble to catch up. Instead of compounding value, you run into a multi-agent productivity paradox: the more agents you add, the harder it becomes to maintain consistency, trust, and control.
Key takeaways:
- Adding more AI agents doesn’t automatically increase productivity, because without shared context and governance, scale can create duplication, inconsistency, and confusion
- Orchestration alone cannot fix multi-agent fragmentation; enterprises need a trusted content foundation with consistent permissions, versioning, retention, and provenance
- Multi-agent productivity compounds only when all agents operate from the same governed, authoritative source of truth across teams and workflows

Creating confusion at scale
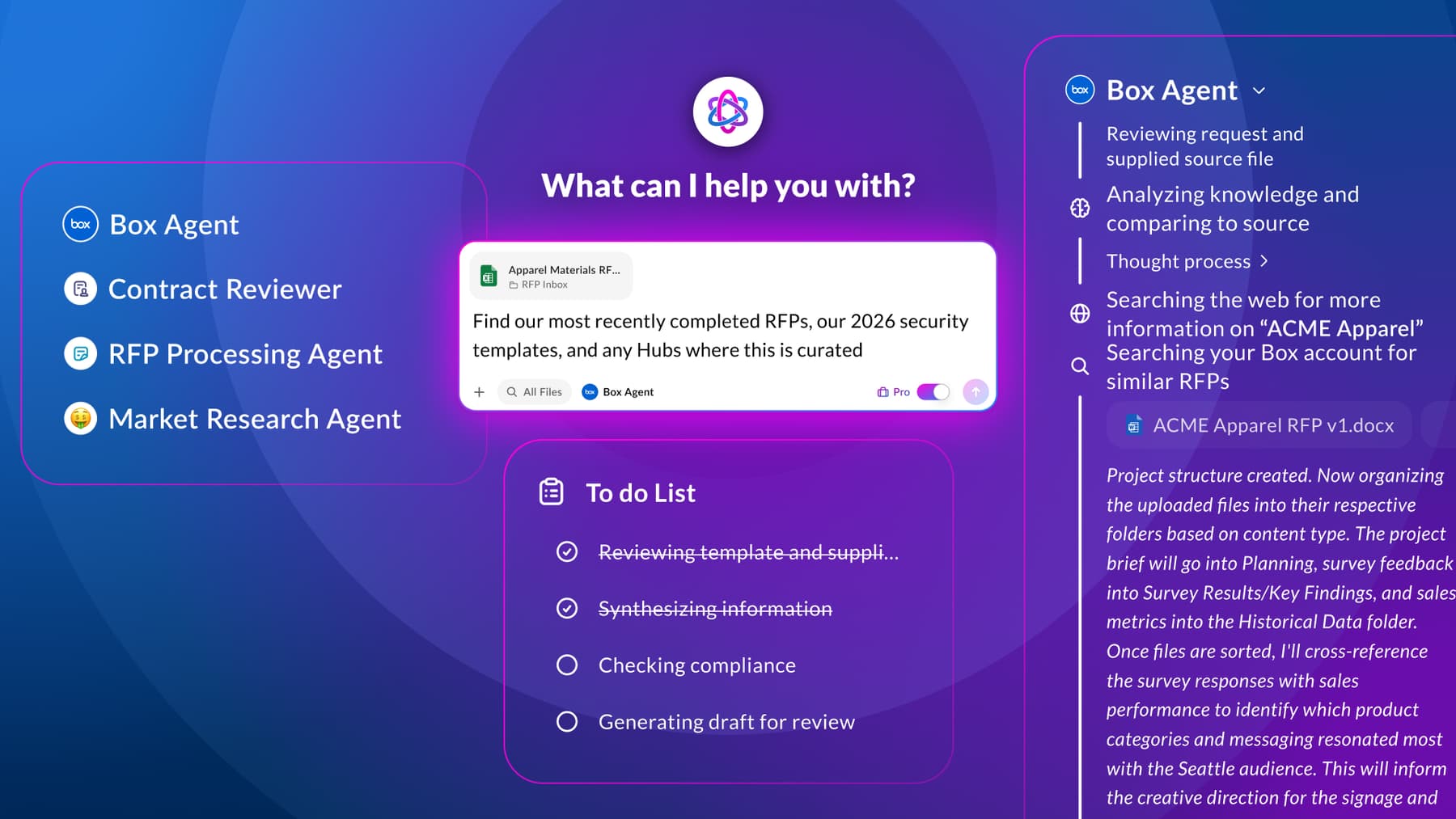
Beyond single-purpose copilots, enterprise expectations are rapidly converging around multi-agent systems as the next stage of AI adoption. But early implementations already show a pattern of fragmentation, with disconnected agent “islands” that can't share context well enough to compound value across the organization.
To be clear, individual agents aren't failing. In fact, each one does exactly what it was designed to do. But when agents act on islands of context, each one operates with only a partial view of the enterprise. One agent drafts from an outdated policy. Another references a different contract version. A third can't access the same records because permissions are inconsistent. A fourth produces an answer with no clear provenance, leaving teams unsure which source it relied on or whether it should be trusted at all. Each runs the risk of introducing duplication, contraction, or policy drift. The organization has added more automation, but not more alignment.
The instinctive response to this mess is often to add another layer of orchestration to sync disconnected content. But you can’t orchestrate your way out of fragmented source material. If the underlying content is inconsistent, poorly governed, or inaccessible in different ways to different agents, then orchestration simply moves confusion around faster. It may sequence tasks more elegantly, but it can't create trust where the underlying context is unstable.
The result is not scaled intelligence, but scaled confusion.
A secure content layer enables clear agent scaling
Agents don’t create value in a vacuum. They retrieve, reason over, and act on enterprise content: contracts, policies, product specifications, knowledge articles, records, and other operational documents. That content is the crucial context agent-driven workflows need.
A unified content layer determines whether your agents work from the same truth or from fragmented approximations of it. When the content layer is authoritative and governed, agents can compound each other’s work. A drafting agent, for example, will pull from the same policy set a review agent uses so there’s no conflict. When the context underneath work is consistent, teams can move a lot faster. (This is true even outside of AI, of course.)
A single content layer also ensures a higher level content security within agentic AI workflows. When agents can retrieve only the information they’re authorized to use, their outputs are far more reliable, explainable, and safe to act on. Instead of generating answers from incomplete or conflicting context, agents work from the right source material at the right time, which prevents policy drift and gives teams more confidence that AI-generated work reflects the business accurately.


What governed content means for multi-agent systems
A governed content layer is not just a repository where files happen to live. For multi-agent systems, governed content means the enterprise can trust the information agents retrieve and act on. There are several factors that go into content governance in the age of agentic AI:
It starts with permissions. Agents should only access what they’re allowed to access, and those controls must be consistent across tools and teams. Without permissioning, organizations face an immediate tradeoff between usefulness and risk. Either agents know too little to be effective, or they know too much and expose the business.
Versioning matters. If multiple agents are working from different versions of a contract, policy, or specification, then the organization no longer has a shared operating picture. Outputs diverge not because the models are broken, but because the source truth is unstable.
Retention matters, too. Enterprises can't scale agents responsibly if those agents act on content that should have been archived, deleted, or managed under a specific lifecycle policy. Retention alignment ensures that AI systems operate within the same information governance framework as the rest of the business.
Provenance is the final piece. In a multi-agent environment, provenance makes outputs auditable and trustworthy. Teams need to know where an answer came from, what source material informed it, and whether that source was authoritative at the time of use. Without provenance, every output becomes harder to validate, and every exception becomes harder to investigate.
When agents pull from inconsistent sources, mistakes spread faster. When they can't share governed context, teams create parallel workflows and duplicate reviews. Governance becomes reactive because the organization is constantly trying to explain or correct what happened after the fact. Messy knowledge and weak governance cause agents to drift or create risk.


Content fragmentation multiplies risk
Every additional agent should strengthen the system, not weaken it. But without a shared, governed content foundation, every new agent increases the surface area for inconsistency. In general, a few well-supported agents will scale better than many disconnected ones.
At Box, we took a sandbox approach to experimenting with AI agents, but eventually, we moved from 100+ experiments to a smaller set of “big bets,” focusing on use cases with high repeatability and critical thinking. We built these highest-impact agents on trusted data, permissions, and knowledge sources.
We also treated rollout as an operational and change-management effort, not just a technical launch. We redesigned workflows so agents became part of daily work rather than optional side tools. We assigned clear ownership for adoption and continuous improvement. And we regularly review how our agentic efforts are working, so scaling remains continuous rather than one-and-done.
The path to compounding productivity
Enterprises should think about agent scale the same way they think about any other critical operating system: not as a collection of isolated tools, but as a coordinated environment built on trusted infrastructure.
For multi-agent systems, that infrastructure is one file system for content. The organizations that successfully scale productivity will be the ones that make content authoritative, permission-aware, versioned, retention-aligned, and provenance-traceable. They’ll give agents a shared context layer that works safely across teams and tools. And they’ll treat governance not as a brake on AI adoption, but as the condition that makes scale possible.
Learn how to create agentic workflow automation on a single secure content layer with Box Automate.


