Enterprises use workflow tools to automate document approvals, route files based on metadata, trigger e-signatures, and orchestrate multi-step processes across departments. It’s deterministic, reliable, and trusted in regulated industries.
When we set out to build Box Automate, our goal was to add AI agents to enterprise content workflows as genuine participants that could reason, make decisions, and act without sacrificing the reliability, auditability, and security that our customers depend on.
That turned out to be a much harder problem than we expected. This post walks through the five hardest design decisions we faced, the tradeoffs we made, and what we learned.


Decision 1: Build for both deterministic and non-deterministic systems
The first decision forced us to confront a fundamental question: what does enterprise automation actually need?
Our initial instinct was to treat AI-driven workflows as the successors to deterministic ones — a next-generation engine that would eventually render rules-based systems obsolete. The logic seemed sound: if AI agents can handle complex, context-dependent decisions, why maintain a separate system for simple trigger-action flows?
We reconsidered after spending time with customers who run deterministic workflows in production. The insight was clarifying: deterministic and non-deterministic workflows aren’t competing approaches. They reflect two genuinely different enterprise needs that coexist, and always will.
When a healthcare organization needs a document to route to a specific reviewer every time a metadata field changes, they don’t want an agent deciding whether that routing makes sense. They want certainty: the same output for the same input, every time, with an audit trail that a compliance auditor can follow without ambiguity. That determinism is a feature, not a limitation.
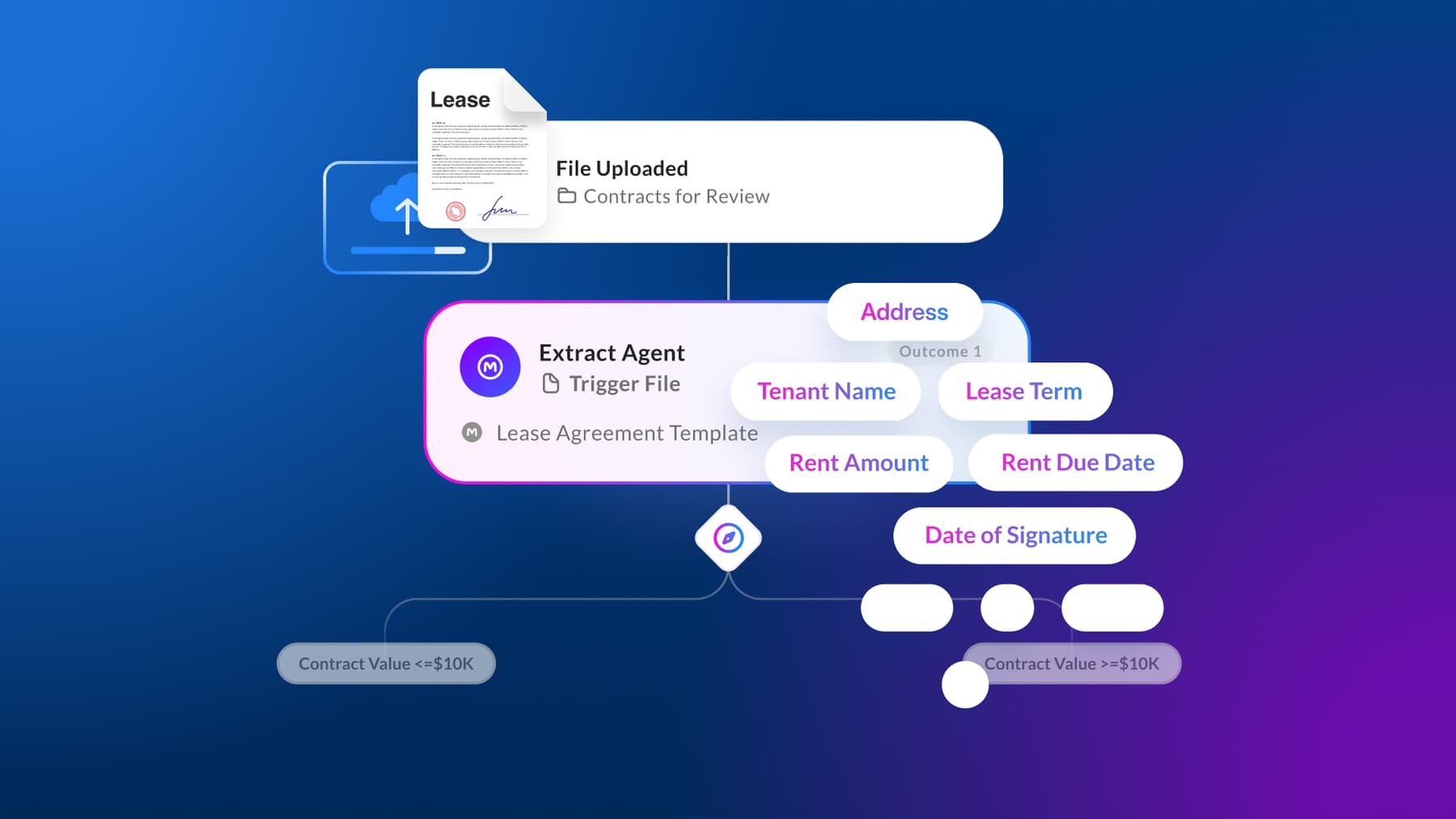

But enterprises also face a growing volume of processes that rules-based logic simply can’t handle: reasoning over unstructured content, making context-dependent decisions, handling inputs too variable for rigid rule sets. That’s where non-deterministic, AI-driven workflows become necessary.
With Automate we designed a solution that lets customers benefit safely from both paradigms by building process automation along a sliding scale, from fully deterministic to fully AI-driven, and every combination in between.
Deterministic steps stay deterministic. Judgment steps get agents. A single workflow can drive an end-to-end process: a Box Forms submission triggers routing and metadata assignment, Box Extract agents parse and populate structured fields, an AI agent reviews extracted data against policy, flags exceptions, and routes decisions based on confidence scoring — all within one coherent system.
The goal was never to unify everything into one model, but to build a platform where both deterministic and non-deterministic needs can coexist, complement each other, and serve the customer without compromise.
Decision 2: Agents as first-class workflow participants
AI is an add-on to most automation platforms; a workflow engine manages steps, transitions, and state, and an AI integration gets called as a service within a step. The workflow engine doesn’t understand what the AI is doing; it just sends a request, gets a response, and moves on. The AI is a black box inside a transparent system.
We wanted agents to be first-class workflow participants — not services that get called, but entities that the workflow engine understands, manages, and governs with the same rigor as human participants or deterministic system steps.
This required rethinking how the workflow engine represents a step.
For agent steps specifically, the engine manages additional concerns: context assembly (what content and metadata the agent can see), confidence reporting (the agent must declare its confidence level alongside its output), and escalation routing (what happens when confidence falls below the threshold configured for that step).

Implementing this vision meant solving the fundamental tension between non-deterministic agents and workflow engines that expects predictability. Our system needed to embrace non-determinism at the step level while maintaining deterministic guarantees at the workflow level, meaning the overall process always completes, produces an auditable trail, and routes correctly, even when individual agent steps produce variable results.
We call this mechanism the confidence-and-fallback pattern. Every agent step can be configured as a confidence threshold. Outputs above the threshold proceed automatically. Outputs below the threshold route to a fallback — typically a human reviewer, but configurable as another agent, a different model, or a deterministic rule. The workflow engine guarantees that every step resolves, even if the primary agent can’t resolve it with sufficient confidence. The result was what we were after: non-determinism at the agent level, deterministic completion at the workflow level.
Decision 3: Content-native context, not API-mediated context
This is the decision most directly shaped by the fact that Box is a content platform, not just a workflow platform.
When agents on other platforms need to reason over documents, they go through a retrieval pipeline: call an API, download the file, parse it, extract text, maybe run it through a vector store for retrieval-augmented generation. Every step in that pipeline introduces latency, potential information loss, and a security question (does this agent have permission to access this file through this API path?).
Box Automate agents operate inside the content platform. They don’t fetch documents through external APIs; they access content natively, through the same metadata-rich, permission-enforced, version-aware layer that every Box feature uses.


This changes what agents can reason over. An agent processing a contract doesn’t just see the text of the contract; it sees the metadata (document type, deal stage, counterparty, expiration date), version history (what changed in the last revision and who made the changes), permission model (who has access, who approved the last version), and relationships to other content (the master agreement this addendum references and the compliance policy that governs this contract type). All this context is available without additional API calls, parsing, and permission checks, because the agent inherits the content platform's existing infrastructure.
The impact on agent reliability is significant. Agents with richer context produce more accurate outputs. An extraction agent that can cross-reference an invoice against the purchase order and the vendor agreement catches discrepancies that an agent working from the invoice alone would miss. A review agent that can see the version history of a policy document understands which clauses were recently changed and merit closer scrutiny, rather than treating every clause equally.
We deliberately chose not to build a separate "agent knowledge base" or "agent memory" system. With Automate, the content platform is the knowledge base and documents, metadata, relationships, and permissions are the memory. This means agents benefit from every improvement to the content platform — better metadata extraction, richer relationship modeling, more granular permissions — without any agent-specific engineering.
Decision 4: Variable autonomy as a first-class concept
Early in Automate’s development, we had a binary model: a workflow step was either "automated" (agent handles it) or "manual" (human handles it). Customer feedback during beta made clear that this was insufficient; the real world has more than two modes.
A healthcare claims processor wanted agents to handle routine claims autonomously but route complex cases to a specialist — not because the agent couldn’t process them, but because the regulatory environment required human judgment above a certain dollar threshold. A legal team wanted agents to draft contract redlines autonomously for standard clauses, but flag non-standard clauses for attorney review. A financial services compliance team wanted agents to process reports with full autonomy during normal operations, but switch to human-in-the-loop mode during audit periods.
These aren’t edge cases; they’re the standard operating reality of enterprise content workflows. We redesigned the autonomy model around a spectrum with four levels, configurable per workflow step:
Full autonomy: The agent executes and the output proceeds without human review. Used for high-volume, low-risk, well-understood tasks where the agent has demonstrated consistent accuracy.
Supervised autonomy: The agent executes, but a human gets a notification with the agent's output and confidence score and can approve, modify, or reject. Used for medium-risk tasks where oversight is desired but bottlenecks aren’t.
Human-in-the-loop: The agent executes and produces a recommendation, but the workflow pauses until a human explicitly approves. Used for high-risk decisions, regulatory-sensitive processes, or tasks where the organization is still building trust in the agent's judgment.
Human-only: The step is performed entirely by a human. The workflow engine manages assignment, notification, and deadline tracking, but no agent is involved. Used for steps that require judgment, creativity, or interpersonal interaction that agents can’t provide.
The autonomy level isn’t static; it can be configured to shift dynamically based on agent confidence scores, document characteristics (dollar value, document type, counterparty risk rating), and external conditions (audit period, regulatory change). A single workflow step can operate at full autonomy for routine cases and shift to human-in-the-loop for exceptions, without the workflow designer building separate paths for each scenario.
This variable autonomy model has become one of the features that our customers cite most frequently. It maps directly to how enterprises actually want to adopt AI: cautiously at first, with increasing trust over time.
Decision 5: Inherited, not built, trust
The security question we heard most often during beta was some variation of, "How do I know the agent only sees what it should see?"
On most platforms this is a hard problem. You build an AI agent, connect it to various data sources, then implement access controls at the agent level. Every new agent requires a new access control implementation. Every data source requires a new permission check. The attack surface grows with every agent deployed.
Box Automate takes a fundamentally different approach. Agents inherit the content platform's existing permission mode. So an agent running on behalf of a user can only access content that user has permission to see. An agent scoped to a folder can only access content within that folder's permission boundary. An agent processing a document respects the classification, watermark, and retention policies that govern that document.
This isn’t a feature we built for Automate; it’s a property of building on a content platform that already has enterprise-grade permission enforcement.
The same inheritance applies to audit trails. Every action an agent takes is logged through the same audit infrastructure that tracks human actions on the platform. There’s no separate "agent audit log;" just one audit system in which agents participate just like humans and system processes.
The practical impact is that deploying a new agent in Box Automate doesn’t require a security review of the agent's access permissions. The permissions are inherited and the security review happened when the content permissions were configured. This dramatically reduces the time and effort required to move agents from development to production, particularly in regulated industries where security review cycles are measured in weeks or months.


The content-to-workflow pipeline
The broader architecture in which Box Automate participates is what we internally call the content-to-workflow pipeline: Forms for data collection, Extract for intelligent data capture, metadata for structured context, Automate for workflow orchestration, Doc Gen for output generation, and Sign for execution.
Each component is independently useful. But the compound effect — a single, permission-aware, auditable flow from content ingestion through intelligent processing to automated execution — makes the system greater than its parts. An insurance intake form is submitted through Box Forms. Extract agents parse the supporting documents and populate metadata fields. Automate orchestrates the review: agents assess risk, cross-reference policy terms, and flag exceptions for human review. Doc Gen produces the coverage letter. Sign routes it for execution.
Every step operates on the same content, with the same permissions, through the same audit trail. There are no integrations to maintain, no permission boundaries to reconcile, and no context lost in translation.
This is what we mean when we say the content platform is the workflow platform. It’s not a metaphor. It’s the architecture.
Building for what comes next
Box Automate is generally available now, and customers already running it in production have taught us a lot.
The direction is clear: more sophisticated agent collaboration within workflows (agents that hand off to other agents, not just to humans), deeper cross-application orchestration through standards like MCP (Model Context Protocol), and richer feedback loops where agent performance continuously informs workflow optimization.
But the foundation — agents as first-class workflow participants, content-native context, variable autonomy, inherited trust — is based on design decisions whose value will compound. They were the hardest decisions to make, and they’re the ones we’re most confident were correct.
Learn more about how Box customers are benefiting from Automate


