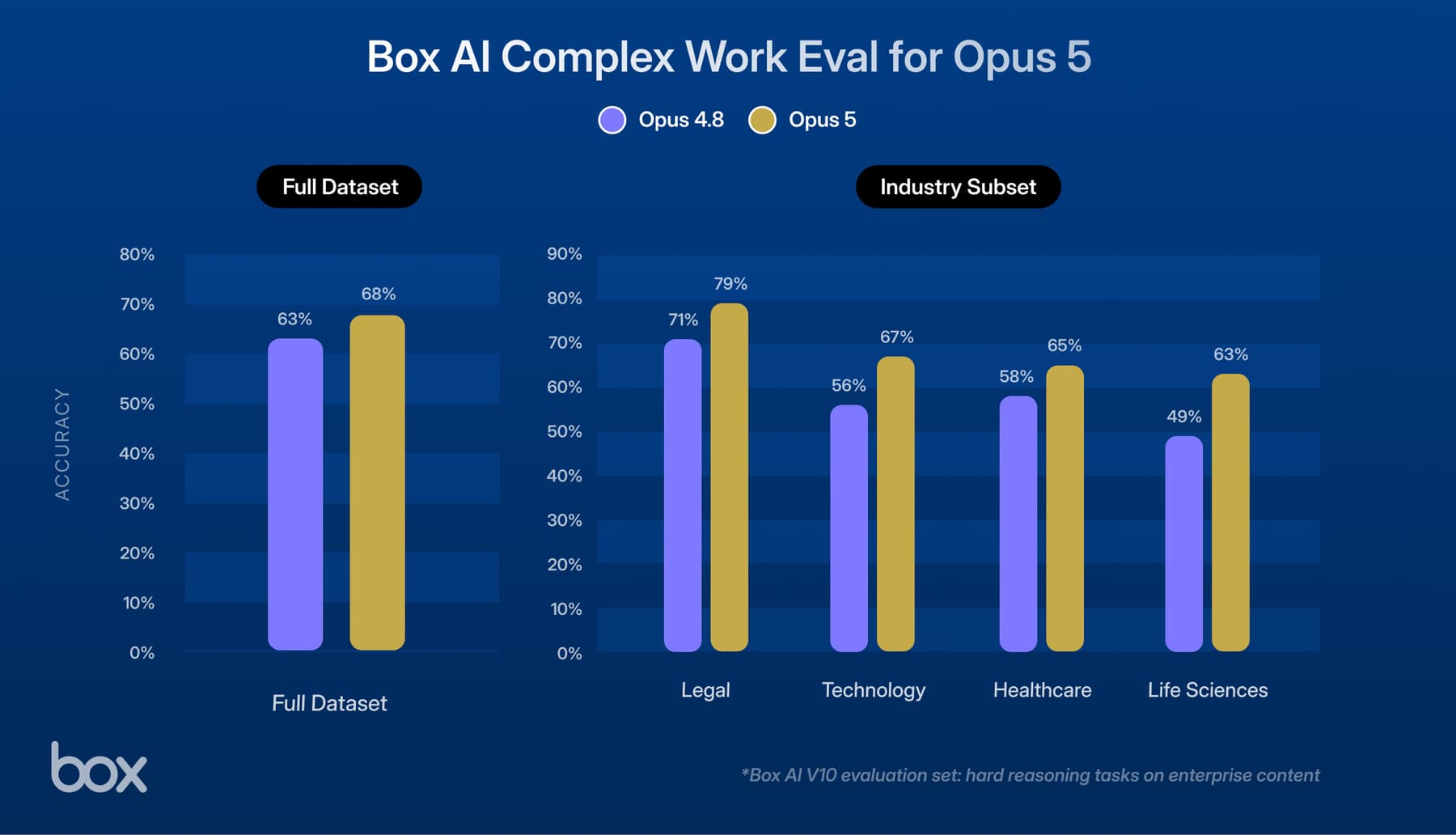
If you've been using Box's AI-powered metadata extraction, you've probably wondered: "How much confidence should I have in this result?" With the release of our new confidence score feature, the /ai/extract_structured endpoint now includes confidence scores at the field level, giving you a probabilistic measure of extraction accuracy.
What are confidence scores?
Confidence scores are numerical values between 0 and 1 that estimate the likelihood that an extracted field value is correct. A score of 0.875, for instance, means there’s roughly a 87.5% chance the extraction is accurate. Think of it as the API telling you, "I'm pretty sure about this one" versus "You might want to double-check this."
The system generates these scores by requesting multiple responses from the LLM and analyzing consistency. When the model returns similar values across different prompts and configurations, confidence is high; when responses vary significantly, the score drops accordingly.
Using confidence scores
Adding confidence scores to your extraction workflow requires a single parameter. Set "include_confidence_score": true in your request:
curl -L 'https://api.box.com/2.0/ai/extract_structured' \
-H 'content-type: application/json' \
-H "authorization: Bearer $BOX_TOKEN" \
-d '{
"items": [{"type": "file", "id": "16550157147"}],
"fields": [
{"key": "document_title"},
{"key": "document_type"}
],
"include_confidence_score": true
}'
The response includes a confidence_score object with scores and confidence levels for each extracted field:
{
"answer": {
"document_title": "Albert Einstein",
"document_type": "Resume"
},
"ai_agent_info": {
"processor": "basic_text",
"models": [
{
"name": "google__gemini_2_5_flash",
"provider": "google"
}
]
},
"created_at": "2025-11-26T02:04:33.194-08:00",
"completion_reason": "done",
"confidence_score": {
"document_title": {
"level": "MEDIUM",
"score": 0.75
},
"document_type": {
"level": "LOW",
"score": 0.375
}
}
}
What the scores mean
Box provides suggested thresholds as a starting point:
- Scores of 0.90 and above indicate high confidence — these extractions typically need minimal review
- Scores between 0.70 and 0.89 suggest medium confidence — consider light review
- Scores below 0.70 signal low confidence — manual review is recommended
These thresholds are guidelines, not absolute rules. They're likely to evolve as the feature matures and more testing data becomes available. Your optimal thresholds depend entirely on your risk tolerance, document types, and the criticality of the extracted data. A 0.70 confidence score, for instance, might be acceptable for tagging documents in a content library where occasional errors are tolerable, but that same score would be unacceptable for extracting financial data where accuracy is non-negotiable.
Understanding the limitations
While confidence scores are valuable for assessing extraction reliability, they have important limitations.
Confidence is not a guarantee. A high score indicates high probability of correctness, but errors can still occur. Even with a 0.95 confidence score, there's always a chance the extraction is wrong. Critical data should always be cross-verified regardless of the confidence score.
Context matters more than you think. Confidence scores reflect the model's understanding of the data, but they don't account for business-specific nuances that a human reviewer would immediately recognize. For example, if you create a field called "company_name" for invoice extraction, the model might struggle to determine which company name you want — did you mean the vendor or the customer — resulting in a lower confidence score even though both values are clearly visible in the document.
This is why providing clear, specific field descriptions is crucial; the more context you give the model about what you're looking for, the better it can assess its own confidence. Instead of "company_name," use "vendor_company_name," or add a description like, "The name of the company issuing this invoice."
Building human-in-the-loop workflows
The primary use case for confidence scores is enabling human-in-the-loop workflows. Instead of blindly trusting all extractions or manually reviewing everything, you can programmatically route low-confidence fields for human verification.
For API users, this requires custom implementation. You'll need to:
- Parse the confidence_score object from the response
- Compare each field's score against your thresholds
- Route low-confidence extractions to a review queue
- Implement a mechanism for humans to correct and confirm values
Common patterns include using confidence scores to prioritize review queues (handle low-confidence extractions first), filter data sets (exclude extractions below a certain threshold from automated processing), or create conditional workflows (automatically approve high-confidence extractions while flagging low-confidence ones for manual review).
Best practices
Provide clear field descriptions. Ambiguous field names and vague descriptions lead to lower confidence scores and less reliable extractions. Be specific about what you're asking for and include context about where the data typically appears in your documents.
Test and iterate. Monitor confidence patterns across your specific document types and use cases. Track how often high-confidence extractions are actually correct, and adjust your thresholds based on real-world accuracy data from your workflows.
Use scores to prioritize, not replace, human judgment. Confidence scores help you allocate review resources efficiently. You can route low-confidence fields to human reviewers while auto-processing high-confidence ones, thus maintaining oversight of the entire system.
Model support and current limitations
Confidence estimation currently works with Google Gemini models (gemini-2.5-flash and gemini-2.5-pro). The model used depends on your configuration, and you can verify which model processed your request by checking ai_agent_info.models in the response.
A few things to note:
- Confidence scores are not persisted or logged. They exist only in the API response. If you need to audit or track these scores, you'll need to capture and store them yourself.
- The feature is currently limited to the /ai/extract_structured endpoint.
Why this matters
One of the most common questions we hear from developers who are implementing AI extraction is, "How do I know when the AI got it wrong?" Until now, the answer was, "Manually check everything or hope for the best." Confidence scores give you a third option: relying on the machine when it has higher confidence and verifying the response when it’s lower.
This is especially valuable for high-volume extraction workflows where manual review of every field is impractical but accuracy still matters. By focusing human attention on low-confidence extractions, you can optimize for both speed and quality.
Getting started
Confidence scores are available now. To start using them, simply add "include_confidence_score": true to your /ai/extract_structured requests. Experiment with different threshold values against your document types, measure the accuracy, and tune your workflow accordingly.
Remember: confidence scores are a tool, not a solution. They tell you where to look, but you still need to build the processes around when to rely on automation and when to bring humans into the loop.
A practical example: Extracting data from a lease contract
Our starting point is a sample property lease agreement:

Many fields can be extracted from this document, including property identification, property type, agreement date, lease start and end dates, monthly rent, and a few more.
On the right you’ll see a metadata template with this data captured.
You can formally describe the fields that you want to capture. For example, let’s capture the lessee and lessor names:
curl 'https://api.box.com/2.0/ai/extract_structured' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ...' \
--data '{
"items": [
{
"id": "1652529260837",
"type": "file"
}
],
"fields": [
{
"key": "lessee_name",
"description": "The name of the person",
"displayName": "Lessee Name",
"prompt": "the person or entity who rents or leases property",
"type": "string"
},
{
"key": "lessor_name",
"description": "The name of the person",
"displayName": "Lessor Name",
"prompt": "owner of the asset who grants the right to use it to another party (the lessee) through a lease agreement",
"type": "string"
}
],
"include_confidence_score": true
}'
Notice the "include_confidence_score": true, that will include the confidence scores in the reply, and the individual prompting for each field to guide the LLM in the extraction, resulting in:
{
"answer": {
"lessee_name": "Marie Tharp",
"lessor_name": "Schiaparelli plaza"
},
"ai_agent_info": {
"processor": "basic_text",
"models": [
{
"name": "google__gemini_2_5_flash",
"provider": "google"
}
]
},
"created_at": "2026-01-15T07:44:32.072-08:00",
"completion_reason": "done",
"confidence_score": {
"lessee_name": {
"level": "HIGH",
"score": 1
},
"lessor_name": {
"level": "HIGH",
"score": 1
}
}
}Another feature of the extract structured is that if we have a metadata template defined, we can use those definitions to execute the extraction:
curl 'https://api.box.com/2.0/ai/extract_structured' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ...' \
--data '{
"items": [
{
"id": "1652529260837",
"type": "file"
}
],
"metadata_template": {
"template_key": "leases_workshop",
"type": "metadata_template",
"scope": "enterprise"
},
"include_confidence_score": true
}'
Resulting in:
{
"answer": {
"property_id": "HAB-1-01",
"property_type": "HAB-1",
"agreement_date": "2024-04-24T00:00:00Z",
"lease_start_date": "2024-05-01T00:00:00Z",
"lease_end_date": "2027-04-30T00:00:00Z",
"monthly_rent": 3125,
"number_of_bedrooms": 1,
"agreement_term": 3,
"lessee_name": "Marie Tharp",
"lessee_email": "[email protected]"
},
"ai_agent_info": {
"processor": "basic_text",
"models": [
{
"name": "google__gemini_2_5_flash",
"provider": "google"
}
]
},
"created_at": "2026-01-15T08:01:36.707-08:00",
"completion_reason": "done",
"confidence_score": {
"number_of_bedrooms": {
"level": "HIGH",
"score": 1
},
"lessee_email": {
"level": "HIGH",
"score": 1
},
"lessee_name": {
"level": "HIGH",
"score": 1
},
"agreement_date": {
"level": "HIGH",
"score": 1
},
"lease_start_date": {
"level": "HIGH",
"score": 1
},
"lease_end_date": {
"level": "HIGH",
"score": 1
},
"monthly_rent": {
"level": "HIGH",
"score": 1
},
"property_type": {
"level": "HIGH",
"score": 1
},
"agreement_term": {
"level": "HIGH",
"score": 1
},
"property_id": {
"level": "HIGH",
"score": 1
}
}
}
Another example: Extracting data from an image

This time the image is not clear at all, let’s see how it does. For example:
curl 'https://api.box.com/2.0/ai/extract_structured' \
--header 'Content-Type: application/json' \
--data '{
"items": [
{
"id": "2109705995157",
"type": "file"
}
],
"fields": [
{
"key": "name",
"description": "The name of the person.",
"displayName": "Name",
"prompt": "Name is the first and last name",
"type": "string"
},
{
"key": "dob",
"description": "The date of birth of the person.",
"displayName": "DOB",
"prompt": "person date of birth",
"type": "date"
},
{
"key": "class",
"description": "Driver license class",
"displayName": "Class",
"prompt": "identified in the document by CLASS",
"type": "string"
},
{
"key": "gender",
"description": "Gender",
"displayName": "Gender",
"prompt": "identified in document by SEX",
"type": "string"
},
{
"key": "state",
"description": "State",
"displayName": "State",
"prompt": "state",
"type": "string"
}
],
"include_confidence_score": true
}'
Resulting in:
{
"answer": {
"name": "SAMPTEO NER",
"dob": "1992-10-13",
"class": "D",
"gender": "X",
"state": "UT"
},
"ai_agent_info": {
"processor": "basic_text",
"models": [
{
"name": "google__gemini_2_5_flash",
"provider": "google"
}
]
},
"created_at": "2026-01-21T12:57:31.438-08:00",
"completion_reason": "done",
"confidence_score": {
"name": {
"level": "LOW",
"score": 0.5
},
"state": {
"level": "MEDIUM",
"score": 0.875
},
"gender": {
"level": "HIGH",
"score": 1
},
"class": {
"level": "HIGH",
"score": 1
},
"dob": {
"level": "HIGH",
"score": 1
}
}
}
Here we have some low and medium scores. The name in the document is quite confusing and the LLM was not able to pick it up at all. The state was also vaguely defined, but it was able to find the correct data.
Confidence scores give you the visibility to build smarter, more reliable extraction workflows. Whether you’re processing thousands of invoices, automating contract reviews, or building document intelligence pipelines, you now have a clear signal, helping you to decide when to rely on the machine and when to loop in a human. We can’t wait to see what you’ll build using this powerful new tool — share your implementations, challenges, and wins with us in the Box Developer Community.