Last week we published about the company brain — sharing context at scale. In this post we explore the same challenge from an enterprise CIO perspective.
AI agents are plentiful in enterprises already. Developers use Claude Code, Cursor, and Codex. Business teams experiment with Cowork. Platform teams are rolling out internal agents. The question for CIOs and enterprise architects is becoming, what do these agents actually know?
Agents need a trusted enterprise knowledge base: curated, permission-aware, versioned, and reviewable knowledge that can be shared across many agents. Without a shared knowledge layer, every agent becomes its own silo, producing different answers, applying different policies, and operating from inconsistent information. At enterprise scale, inconsistency becomes operational risk. The organizations that succeed will invest early in the knowledge layer.

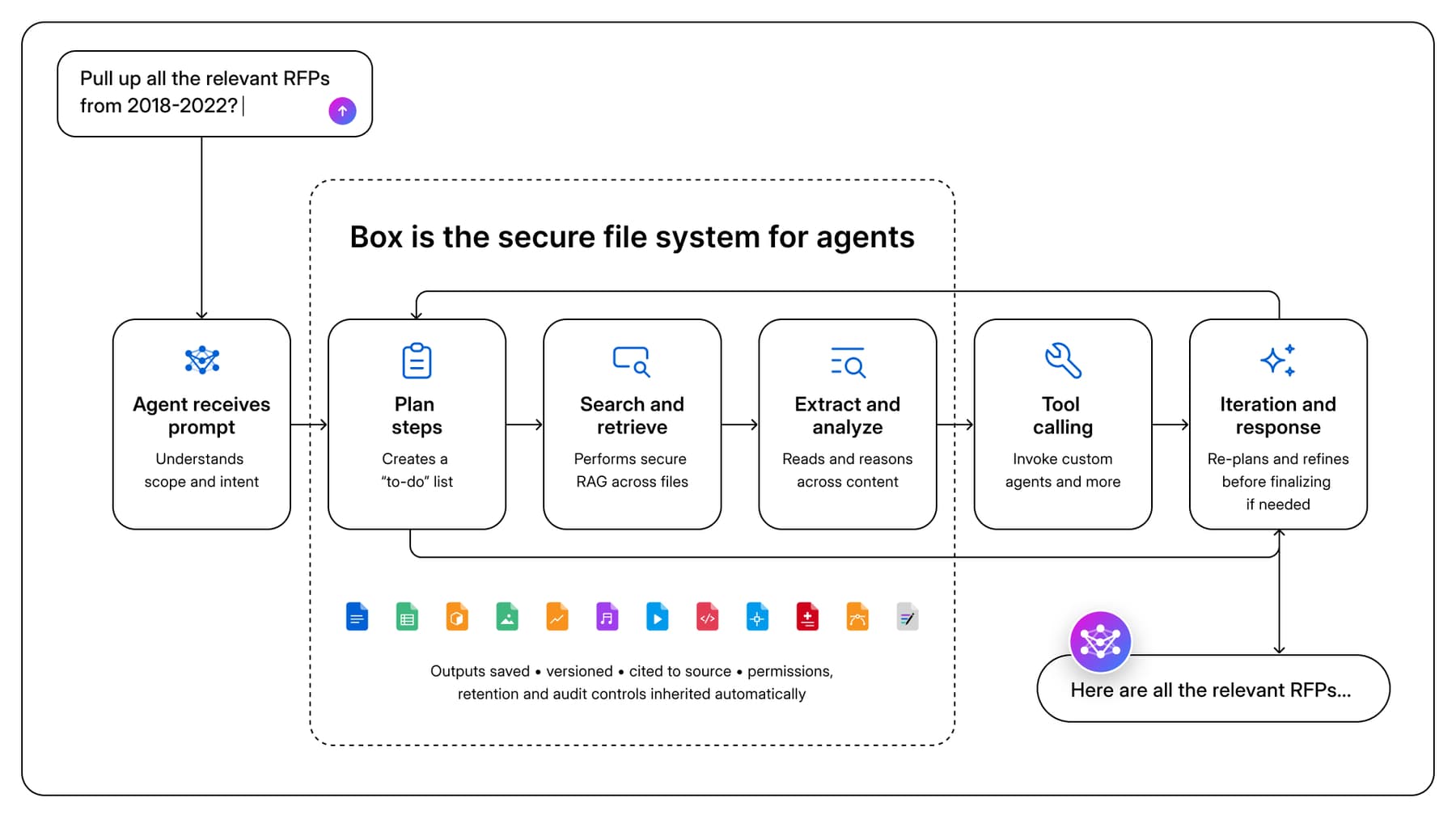
From document retrieval to enterprise knowledge layer
Enterprise content is often scattered in various siloed applications and data stores. Repositories contain outdated documents, conflicting guidance, duplicates, and incomplete context. A curated knowledge base reduces ambiguity and creates a trusted source of truth, thus maximizing agent usefulness. A knowledge base captures what the organization wants agents to use: architectural patterns, security practices, onboarding playbooks, compliance rules, support guidance, decision logs, and operating procedures.
The best knowledge bases are domain-based, not generic. Security teams should maintain security guidance. Governance teams should maintain standards and checklists. GTM teams should maintain positioning and competitive intelligence. Ten high-quality documents in the correct domain often outperform hundreds of loosely related files. In our experience building knowledge bases for internal agents, focusing on curating better knowledge is more impactful than indexing more content.
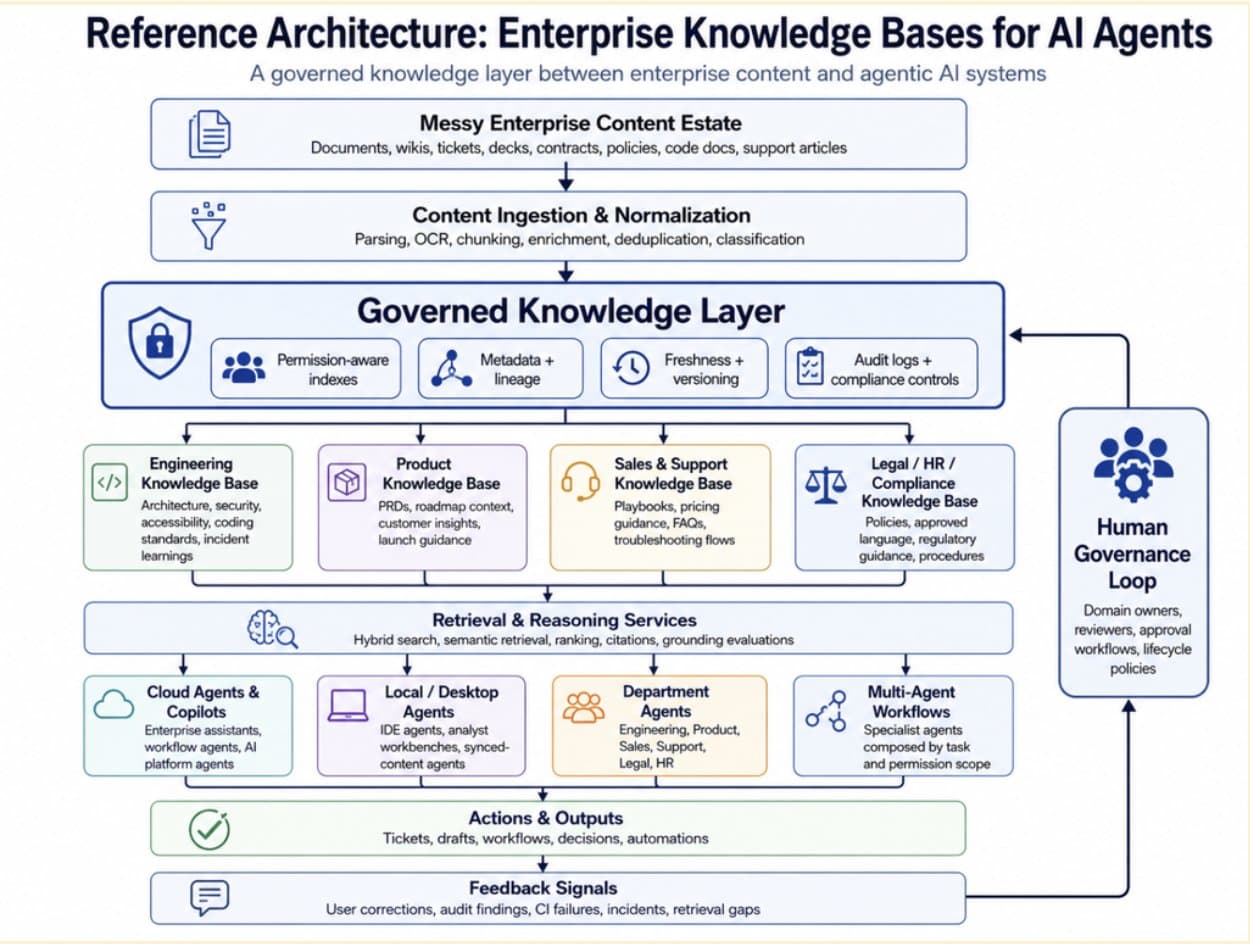
The knowledge layer shouldn’t fragment
Enterprise AI will surface in many places. Developers will use coding agents. Product managers will use structured workflows. GTM and Legal teams may use cloud agents, etc. That fragmentation is normal. It’s also why the knowledge layer matters.
A local agent may need synced files. A cloud agent may need permission-aware access through APIs or MCP. Departmental workflows may need curated domain hubs and deterministic rules tied back to source rationale. Enterprises require these agents to operate on the same knowledge substrate. That means the enterprise knowledge base should be:
- Shared rather than copied into every agent workspace
- Permission-aware
- Versioned
- Reviewable and approvable
- Accessible through APIs, MCP, local files, and workflow integrations
- Usable in both human-readable and machine-readable formats
- Governed and auditable
These aren’t optional features; they’re the controls that make AI-generated work trustworthy.
Box natively provides all these capabilities: Box Drive as a surface area for local agents, APIs and MCP server with appropriate admin controls, permission aware and auditable governance, Box Hubs as curated domain specific content sites.
The Hub model: one domain, one curated knowledge base
For enterprise architects, the design principle should be simple: one hub per domain. Rather than building one giant enterprise brain, create focused knowledge bases for security, architecture, accessibility, legal, compliance, customer onboarding, product operations, and other domains.
Each domain team owns its hub. They curate content, define metadata, review updates, and decide what should become a deterministic rule. Agents then combine the hubs they need for a task.
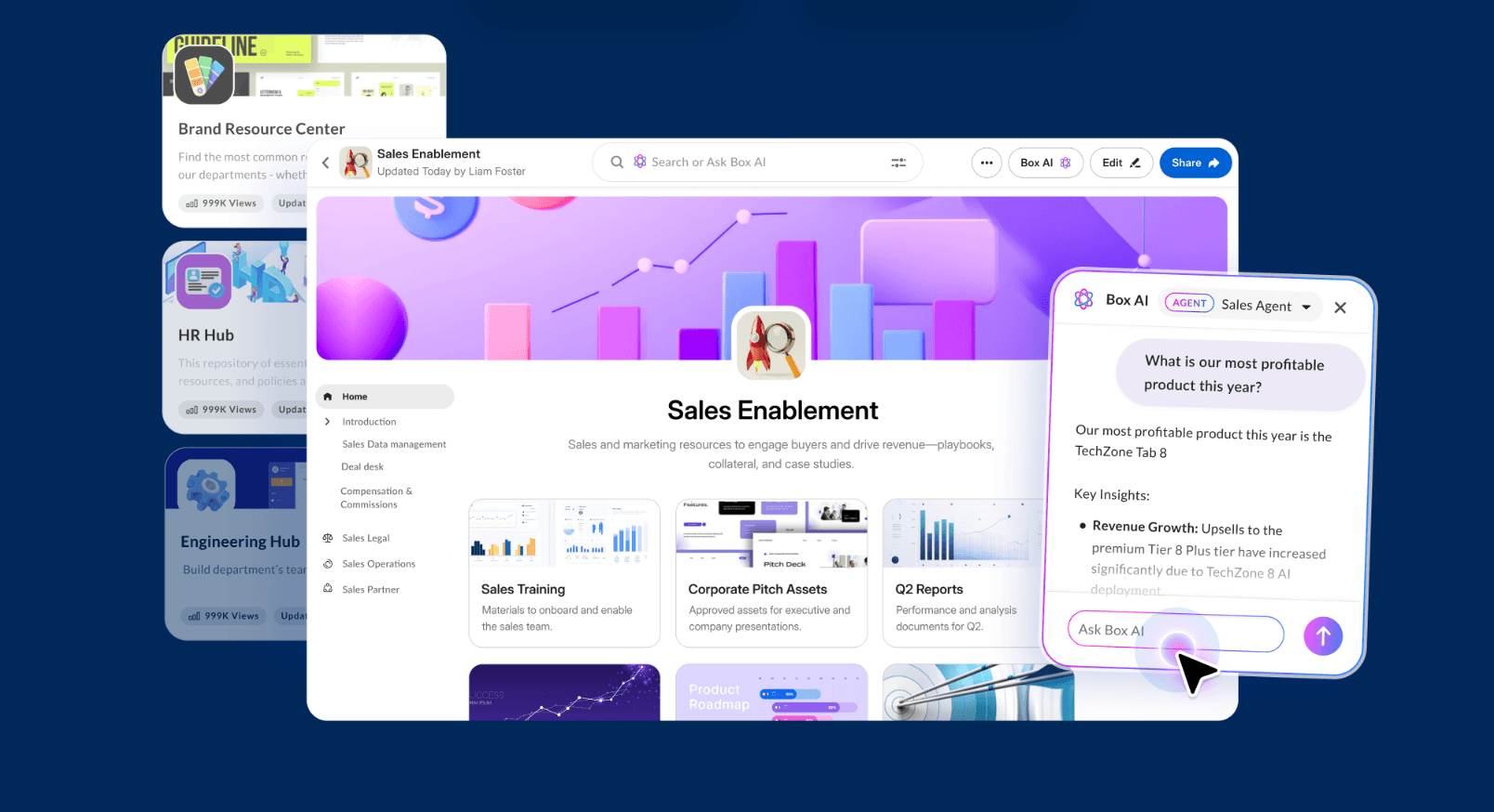

This ownership model matters because enterprise knowledge requires accountability. Without clear ownership, quality degrades over time.
The result is a modular system. A product-planning agent may use product, legal, and security hubs. A code-review agent may use architecture, security, and accessibility hubs. The knowledge base becomes a reusable enterprise capability.
The flywheel: knowledge must improve as agents work
The default failure mode of enterprise knowledge is drift. Policies become stale. Best practices remain trapped in individual teams. Agentic systems create an opportunity to reverse that.
Every workflow generates signals: missing context, failed validations, repeated review comments and policy exceptions. Those signals should feed back into the knowledge base. Domain owners can update source material, improve instructions, refine checklists, or create new rules.
Over time, the knowledge base becomes more valuable because the organization’s work (by both humans and agents) continuously improves it. An example workflow is shown in the following video.
The CIO takeaway
Enterprises don’t need more disconnected agents; they need a shared file system for AI that allows many agents to operate consistently. Models and agent frameworks will change. Interfaces will fragment. But every enterprise will need a trusted knowledge layer that agents can read, cite, and respect.
For CIOs and architects, the mandate is clear: don’t let every team build its own isolated agent memory. Build the enterprise knowledge substrate. Start with a domain where quality matters and rules are clear: security, accessibility, compliance, customer onboarding, or product architecture. Curate the source material. Define ownership. Add metadata. Expose it through the right access paths.
Most importantly, treat the knowledge layer as enterprise infrastructure rather than an AI feature. The next phase of enterprise AI is about smarter organizational memory. The companies that build that memory as a governed, reusable, permission-aware knowledge layer will have an advantage every time a new agent enters the enterprise.


