Businesses collectively spend tens of billions of dollars each year trying to extract key data points from contracts, invoices, claims forms, and all the other unstructured files that accumulate across every enterprise. Manual data entry can sometimes cost organizations thousands per employee annually, while also leading to significant time delays, costly errors, and potential data loss.
The technology unlock is generative AI. For the first time, technology can understand text the way humans do. But by itself, agentic AI is not the full solution to the problem. Uploading documents to an LLM and hoping for accurate extraction is like having a brilliant analyst but no filing system, no quality control, and no memory of what they've already reviewed.
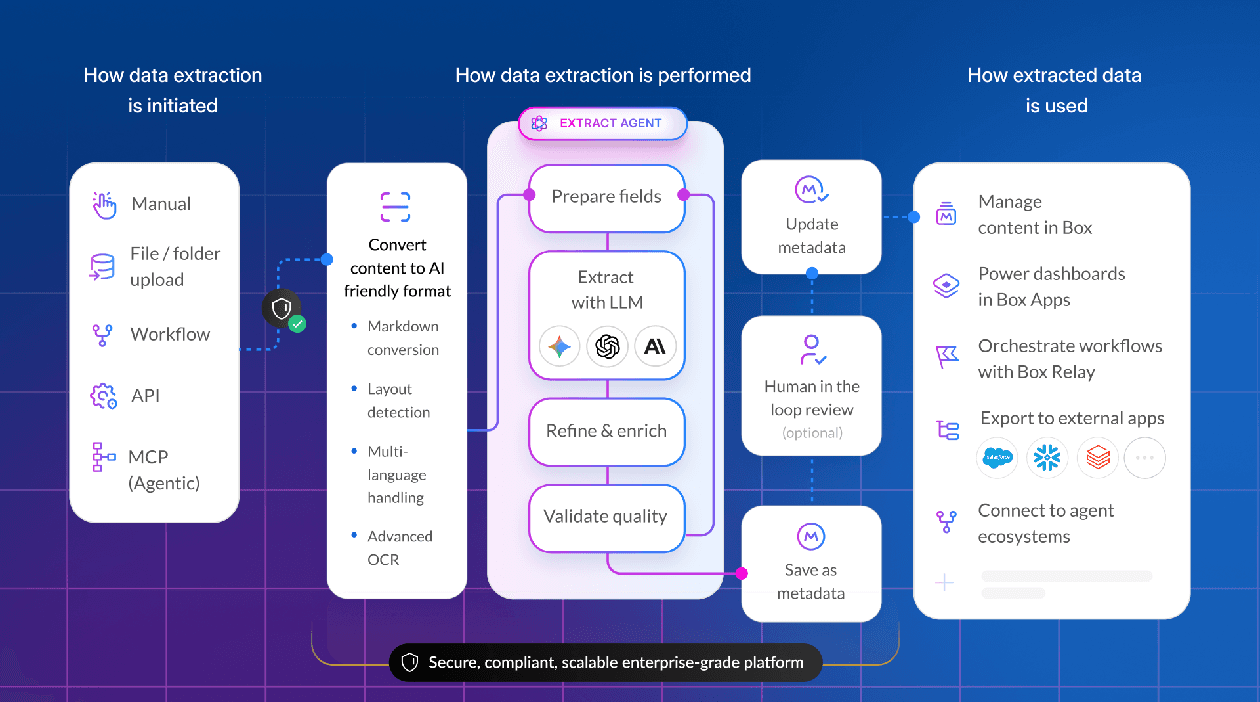
What enterprises actually need are AI agents operating within a content management platform — specialized systems that reason through documents methodically, understand layout and structure, and maintain the governance framework that compliance teams require. And extraction is only the beginning. Enterprises also need to store the files, associate the structured data with the unstructured source documents, and make both available for collaboration and downstream workflows.
Box has developed a series of technical innovations to make this possible, including advanced layout understanding, focused context creation, and custom chain-of-thought reasoning that delivers accuracy improvements over standard approaches. In this article we’ll explain why these innovations matter and how they work.
From IDP to agents: The evolution of document extraction
The market for document extraction currently falls into three distinct categories, each with fundamentally different architectures and tradeoffs.
1. Traditional intelligent document processing (IDP)
Classic IDP platforms use machine learning to classify documents and extract specified fields. They achieve high accuracy, but only for documents with consistent layouts, and only after extensive training.
"Historically, these systems were based on very specific document types," explains Ben Kus, Box's CTO. "Customers typically only did it for things that were very high volume, and they missed out on having valuable data extracted from other documents."
2. Single-shot LLM extraction
Starting in 2023, large language models appeared to offer a breakthrough: flexible extraction without custom training. Most AI models today (including direct API calls to Anthropic, OpenAI, or Google) have this fundamental capability. The approach is straightforward: Upload a document, prompt the model to extract specific fields, receive JSON output.
But basic LLM approaches struggle to meet enterprise requirements.
- Handling diverse formats: AI models typically work best when the information is presented as text or markdown, but enterprises use a variety of document types (documents scanned to PDF, images, complex tables, and more) that can confuse LLMs — and in some cases, they simply won’t work
- Ensuring accuracy: Although AI models are capable of extracting data, they’re not purpose-built for this task, and require careful prompting to ensure they provide reliable, accurate results and avoid hallucinations
- Managing at scale: Processing thousands of documents requires orchestration, error handling, and cost management that raw API calls don't provide
- Context limitations: Some of the most critical information can be long and complex (like contracts, leases, project plans, research documents, etc.),often comprising hundreds of pages or more
- Evolving with technology: Model updates can silently change extraction behavior; enterprises need abstraction from the underlying models
- Meeting security and compliance requirements: When using AI models, you need to ensure they’re used in a secure and compliant way that respects certifications like FedRAMP and HIPPA
3. Agentic extraction
The third approach builds on the power of AI technology. Rather than just applying an LLM in a single pass (which will be brittle and inaccurate, in many cases), a more accurate and flexible approach is to use the power of agentic AI. Agents can apply the intelligence of AI models to not only understand documents, but also figure out the best way to extract the data. For instance:
- Spending more time on complex fields
- Cross-referencing answers for accuracy
- Thinking and reasoning when unsure of the validity of an answer
In general, this approach is similar to how people handle the real-world challenges of extracting information from unstructured data.
Agents can apply the intelligence of AI models to not only understand documents, but also figure out the best way to extract the data.
"At some point, the complexity of what you're trying to get — the number of fields, the instructions per field — becomes so complicated that it doesn't work as well as you might want," says Kus. "So what do you do? Make it an agent. Have it not just go through and pull out the data, but also break it down, get a few fields at a time, have a grader check its work."
And those agents can reason like humans. They can understand different document types better. They can do things like assess whether a clause in a particular contract seems "risky" — not just extract its text. They can choose to "think harder" about more complicated problems. And they can work as part of a team, with other agents coming in to double-check their work.
The technical principles behind AI-powered extraction
The concept is straightforward; the engineering is not. Building agentic extraction that performs reliably at enterprise scale across millions of documents, dozens of formats, and strict compliance requirements demands specific architectural choices. Box has developed three technical principles that make this possible, each addressing a fundamental limitation of sending raw documents to LLMs.
Principle one: Layout understanding
Traditional OCR converts scanned documents to machine-readable text, but the output is a stream of characters with no understanding of document structure. A table becomes a jumble of values. A form with multiple columns becomes an indecipherable sequence.
"When we get any document, whether an image or a PDF, we run OCR to extract the textual representation," Box Agentic AI Product Leader, Norbert Raus, explains. "But we also have layout understanding. We identify what content blocks exist. There's a paragraph, a table, handwriting, an image, a graph — about eight or nine types of content. And we understand precisely the locations. If you're asking for a signature and it's in a stamp with handwriting, we can isolate exactly that type of block."
Agents can handle the complexity of extracting text from handwriting, parsing complex tables, detailed chart analysis, and more. An orchestration layer routes each component to the appropriate specialist, then reassembles the results.
Agents can handle the complexity of extracting text from handwriting, parsing complex tables, detailed chart analysis, and more.
Principle two: Intelligently pre-process content to help the AI model
When you upload a 50-page contract to an LLM and ask it to find the payment terms, the model must process the entire document to locate a few relevant paragraphs. Most of what it reads — party names, boilerplate language, signature blocks, exhibits — is noise that degrades accuracy and increases cost.
Agentic extraction inverts this single-shot approach. Instead of sending everything to the model, specialized agents first identify which parts of the document are relevant to each field being extracted. Two techniques make this possible:
- Named entity recognition (NER) enhancements identify fields containing information about individuals, organizations, locations, and dates, making it easier to prioritize relevant content
- Model-based chunk re-ranking uses document layout and field requirements to prioritize the most relevant sections — when searching for addresses in a 50-page contract, the agent gives more weight to text formatted like mailing addresses found under headings like "Location"
The result: smaller, more focused context windows sent to external LLMs, which increases accuracy while reducing API costs. "Providing a smaller, more focused context to LLMs yields way better results," says Raus. "Those results are also stable — they are not variable between different calls. That's one of the foundational principles."
When smaller, more focused context windows are sent to external LLMs, it increases accuracy while reducing API costs.
Principle three: Agentic reasoning
One key capability of agentic extraction is self-correction. Unlike basic LLM approaches that process a document once and return results, agentic systems reason about what to do next and know when to double-check their work.
"We do the first pass, pick the right agents for the content type and extract information," explains Raus. "Then the agent reflects: ‘Is this instruction ambiguous? Did I use the right context? Maybe I should try different tools or different agents.’ The agentic approach tries to resolve doubts as much as it can before returning results."
Unlike basic LLM approaches, agentic systems reason about what to do next and know when to double-check their work.
Box enhances this iterative reasoning with custom chain-of-thought prompting. "There's IP in how we formulate prompts to the LLM in order to be quite specific and robust in metadata extraction," says Raus. The result: accuracy improvements of up to ten percentage points over standard approaches, particularly for fields requiring logical reasoning. When determining contract end dates that aren't explicitly stated, for example, the agent reasons through term lengths, renewal clauses, and effective dates — trying multiple approaches if the first attempt is uncertain.
Why this matters to CIOs
The bottom line? Three principles that together enable superior extraction results, with layout understanding creating the ability to choose relevant content types and the right set of agents and parameters delivering improved accuracy.
The results are striking for any organization. Insurance firms processing claims can now extract data from handwritten notes, photographs of damage, and scanned forms in a single workflow. Banks analyzing loan applications can parse complex tables showing payment history alongside narrative descriptions of employment. The ability to route different content types to specialized agents means enterprises can process the full diversity of documents they actually receive — not just the clean, consistent ones.
Intelligent pre-processing of content means legal departments scanning thousands of contracts can flag those up for renewal or containing non-standard terms, without the cost of sending every page of every contract through an LLM. CFOs reviewing purchase agreements can identify redundant vendors across thousands of documents.
And because focused context creation sends only relevant sections to the model, sensitive information in other parts of the document never leaves the secure environment, reducing exposure and simplifying compliance reviews. The approach makes extraction both economically and operationally viable at enterprise scale. And extraction systems that can reason through ambiguity and self-correct reduce the burden on human reviewers, who can focus on genuinely difficult cases instead of checking every field.
Extraction requires a content management platform
Standalone extraction tools face a fundamental limitation: The extracted data has to live somewhere, and it needs to stay connected to the source documents.
"Other systems require you to store the data in some database and manually cross-reference and custom-develop a solution," says Kus. "Box lets you store the unstructured data, extract it, store the extracted data, then query it — all in the same system."
Box lets you store the unstructured data, extract it, store the extracted data, then query it — all in the same system
Native integration also solves the governance problem. Box ensures extraction only happens on documents the user has access to. The extracted metadata inherits the same permissions as the source file. And once extracted, that metadata powers dashboards, search, and automation without requiring custom integrations.
"Ultimately, it boils down to being able to trust the process," says Kelash Kumar, VP Product Management, Agentic AI Workflows at Box, "because that's the only way that you can have agentic systems work."
From content to context
Ninety percent of enterprise data is locked in unstructured files. Generative AI created the capability to understand that content. But understanding alone isn't enough. Enterprises need extraction that's accurate, governed, and integrated into how they actually work.
Enterprises need extraction that's accurate, governed, and integrated into how they actually work.
That requires AI agents, not just AI models. Agents that reason methodically through documents rather than processing them in a single pass. Agents that understand layout and structure. Agents that operate within the security and compliance framework of the content platform itself.
"What we're doing is structuring the content such that you can make it actionable," says Kumar. "That action could be automating a process. It could be building new processes with AI in them. But Box Extract is the key to being able to unlock that power."
Learn more about how Box Extract can help you unlock critical data within your content.