If you’ve experimented with building your own document processing pipelines, you’ve likely thought, "Why buy a solution? I can just send this PDF to Gemini or GPT-4 and get the answer."
It’s a common misconception that extraction is just an LLM prompting problem. The reality is that building a production-ready extraction pipeline that handles messy scans, enforces enterprise permissions, and outputs structured, queryable data is significantly harder than a single API call.
We’ve moved beyond simple "RAG" into agentic extraction. Here’s a look under the hood of the new Box Extract’s full-stack, AI-native architecture.

1. The trigger layer: flexibility first
In a real-world application, extraction isn't always a linear process. The Box Extract architecture supports multiple entry points:
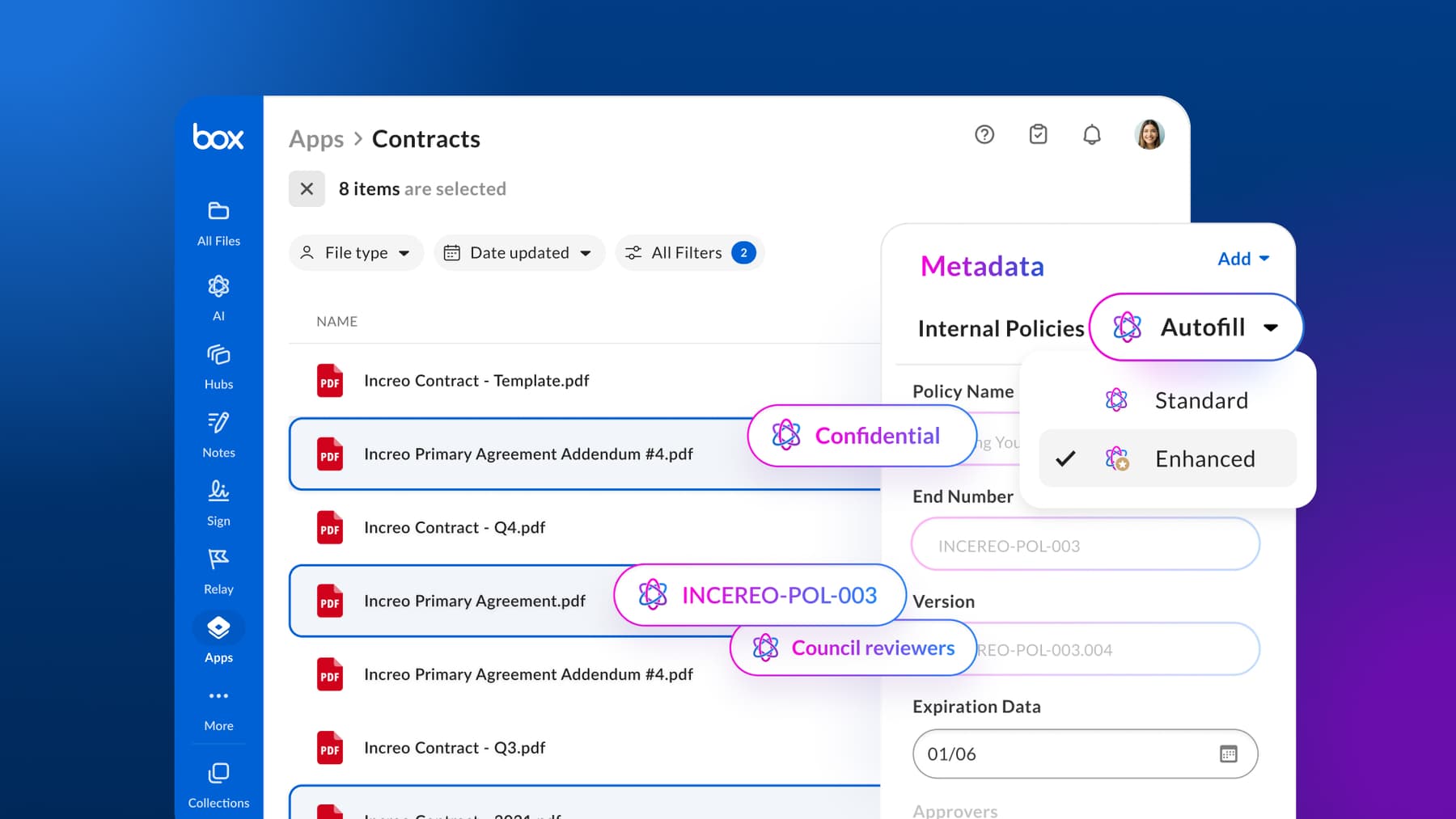
- Manual: A user clicks the 'Autofill' button while reviewing a document in Preview within the Box web app.
- File Upload (Automatic): Triggered instantly upon file upload or modification.
- Workflow & API: Integrated into larger business logic pipelines or called programmatically.
- MCP (Agentic): Triggered by Model Context Protocol agents acting on behalf of users.
2. The core: Why "just an LLM" isn't enough
Once triggered, the data enters the Box Intelligent Extraction Core. This is where the heavy lifting happens, orchestrated by a central intelligence — the Box Extract Agent.
A. Secure, Digitize, and Prepare Before any processing begins, the system verifies security permissions. The agent must have explicit authorization to access the specific file, a "permissions-first" approach critical for enterprise compliance.
Next, we don't just pass a raw PDF to a model. The system prepares the content through integrated, advanced OCR, converting messy documents into a clean, AI-friendly format that preserves structure and hierarchy.
B. The Power of the Box Extract Agent The prepared content is then handed to the Box Extract Agent, the brains of the operation. This isn't a "fire and forget" generation. The agent is a planner and orchestrator that intelligently directs the extraction process through several key steps:
- Categorize: The agent can first classify the document type to determine the best extraction strategy.
- Refine & Enrich: It doesn't just pull text; it refines and enriches the data, potentially cross-referencing it with other sources or taxonomies.
- Validate: The agent verifies the extracted data against predefined business rules and confidence thresholds.
C. Human in the Loop Crucially, the architecture includes a Human in the loop reviews step. For low-confidence extractions or sensitive documents, the process can be routed for manual review before finalization.


3. Store and Update: The power of metadata
Once validated and reviewed, the final step is tosave as metadata. By attaching the newly structured data directly to the unstructured file, we marry the content with the data. This transforms a static file into a database record that’s instantly ready for action within the Box architecture.
4. Data consumption & integration: What you can build
Once the data is extracted and stored as metadata, it becomes an active asset. Here’s how you can put that data to work:
- Manage content in Box: Transform static files into structured records. You can search, filter, and sort content based on the extracted fields—finding contracts by "Value > $10k" rather than just keyword matches.
- Power dashboards in Box Apps: Use the structured data to drive custom views, portals, and visual dashboards directly within Box Apps.
- Orchestrate workflows with Box Relay: Use metadata values to automatically trigger downstream business processes, assigning tasks or routing documents based on the data inside them.
- Export to external apps: Send clean, structured data directly to your other systems of record, such as Salesforce, Snowflake, or Databricks.
- Connect to agent ecosystems: Enable third-party AI agents and external tools to access and read the structured metadata to perform autonomous tasks.


The developer "win:" No operational debt
Perhaps the biggest advantage for developers using Box Extract isn't just the AI—it's the infrastructure.
- No more 429 errors: Box SDKs automatically monitor and manage API consumption. We handle the throttling and concurrency logic so you don't have to write defensive code to prevent "Too Many Requests" errors.
- Structured vs. freeform: Whether you need structured extraction for standardized invoices or freeform extraction for exploratory queries on contracts, the API adapts to the use case.
Compliant, secure, all-in-one place
Everything in Box Extract runs on a secure, compliant and scalable enterprise-grade platform. Your documents never leave your security perimeter, extraction happens with full audit logging, and access controls are enforced at every step. It's safe, secure AI that meets enterprise requirements.
The bottom line
Box Extract isn't just a wrapper around a model. It’s a compliant, secure, all-in-one pipeline, thoughtfully designed to handle the hard parts of production document AI. It enables you to convert messy real-world documents into AI-readable formats, use agentic workflows that know when to iterate and refine, maintain security and compliance throughout, and store results in a way that integrates with your existing Box workflows.
If you're building document workflows, Box Extract gives you a production-ready extraction system backed by years of R&D — so you can focus on your application logic instead of wrestling with PDFs and prompt engineering. The future of document processing isn't about making one LLM call. It's about intelligent agents that know how to orchestrate the right tools at the right time — and that's exactly what Box Extract delivers.