A typical small Mesopotamian clay tablet from around 4,300 years ago, the kind that survives in museum collections by the thousand from the Old Akkadian period, records the sale of a field.
It names the buyer. It names the seller. It states the price in silver. It lists witnesses. It carries the impressions of one or more cylinder seals, the period's equivalent of a notarized signature. The tablet was filed in a room with other tablets in its category, and could be retrieved when, years later, someone wanted to know who actually owned that field.
Strip off the cuneiform and you have a contract management system. It has parties, terms, provenance, tamper-evidence, retention, and addressable retrieval. Every property a modern enterprise needs from a contract today is on that tablet, etched in clay, from before the alphabet had been invented.
I bring this up because every couple of years a fashionable claim resurfaces that the file is dying. You hear it in pitches for AI-first hardware that promise a world without apps or documents. Most of those attempts haven't gone well. You hear it in the marketing of agent platforms whose central premise is that nobody will ever need to open another file. You hear it every few months on tech Twitter, where folders, filenames, and the document itself get declared interface choices from a previous era.
The argument always lands in roughly the same place: If you can just ask a model for what you need to know, why would you still need a document?
After a few years of watching enterprises put AI agents to work on their real content, I've ended up unfashionably convinced of something slightly different. Agents aren't killing the file; they're the strongest reason in a generation to take the file seriously. What's changing is which properties of our files matter most, and how hard we now have to work to preserve them.
Agents aren't killing the file; they're the strongest reason in a generation to take the file seriously.
First, a note on terms. When I say "file" in what follows, I don't mean the desktop icon, the folder tree, or the particular way an operating system happened to expose storage in 1995. I mean a unit of recorded knowledge with stable identity: a contract, a memo, a research note, a regulation, a record of a transaction. Whether it lives on a file system, or in a content management system, object store, or database row is mostly incidental. The load-bearing property is that an institution treats some artifact as the canonical thing for some piece of knowledge, and is willing to be held accountable to it.
In an enterprise, that artifact is a file in an older and more useful sense. It’s business context made durable: the contract that governs the deal, the policy that constrains the workflow, the invoice that proves the transaction, the deck that captures the decision, the research note that explains why the team believed what it believed. If agents are going to act on behalf of a business, this is the ground they’ll have to stand on.

The properties have been stable for a very long time
The substrate of records has changed many times. Clay. Papyrus. Parchment. Paper. Punch card. Magnetic tape. Hard disk. Object store. Every change felt, at the time, like the obsolescence of what came before. None of them actually was.
What didn't change across those transitions is a small set of properties that any record useful to a non-trivial society must have. A record needs an identity: you must be able to point at it. It needs provenance, so whoever reads it later knows where it came from and whether someone has tampered with it. It needs access control, even if access control means "kept in a sealed jar in a temple complex and only the priests have the keys." It needs versioning, even if versioning means "and then we superseded the prior covenant." And it needs structure, even if the structure is implicit in the document’s genre.
Every era of information technology has been a fight over those properties under a new substrate. The fight is what's interesting, because it tells you which property is currently under threat.
Crisis #1: too much commerce for human memory (c. 3200 BCE)
Proto-cuneiform, the earliest direct ancestor of writing as we know it, appears in southern Mesopotamia around 3,200 BCE, give or take, which puts the lineage at something north of five thousand years. The reason it appeared is that Mesopotamian trade had outgrown the cognitive capacity of anyone trying to keep accounts in their head. The earliest writing isn't poetry. It's receipts.
Before tablets, Mesopotamian merchants used a system called bullae: small clay envelopes containing little tokens shaped like the goods being shipped. Three cones for three measures of grain, a disk for a sheep. The envelope was sealed in front of witnesses, and when a shipment arrived, the recipient broke open the bulla and verified the count.

That's a tamper-evident object with physical integrity guarantees, 4,000 years before any of this work showed up under that name in computer science. It also has an obvious scaling problem: you can't read a bulla without destroying it. The leading account of what happened next is Denise Schmandt-Besserat's, debated but influential. Scribes started pressing the tokens onto the outside of the envelope before sealing it. Once you do that, you eventually realize you don't need the tokens or the envelope, just the impressions.
That’s one of the plausible explanations for the origin of writing itself. The first property under pressure was integrity, and a more durable record was the response.
Crisis #2: too many records for a single archive (c. 250 BCE)
By the third century BCE, the Library of Alexandria held somewhere between half a million and seven hundred thousand scrolls, depending on whose count you trust. Nobody could find anything. The scholar Callimachus produced a catalog called the Pinakes, or "Tables of Persons Eminent in Every Branch of Learning, Together with a List of Their Writings." Around 120 volumes of metadata, organized by genre and author, describing the scrolls in the stacks.

As far as we know, that's the first time in recorded history that a society built a serious metadata layer on top of its content because the content had grown too large to navigate directly. Callimachus didn’t invent the scroll. He invented the index. The property under pressure was addressability, and structured metadata was the response.
The pattern is already visible. Every time the volume of content outpaces the existing way of accessing it, the next layer up gets reinvented. The artifact below (tablet, scroll, codex) survives. It just ends up wrapped in more discipline.
Crisis #3: too many copies, not enough trust (1450-1700)
The printing press was a permissioning disaster. Before Gutenberg, a manuscript was de facto access-controlled by the cost of copying it. Producing a Bible took a monastery a year. There were only so many copies, and you mostly knew where they were.
Print collapsed those economics in one generation. Pamphlets, indulgences, forgeries, unauthorized editions, and outright fraud became a continent-wide problem within decades.

The response was institutional. The modern chancery, with its seals, copybooks, registered correspondence, and clear chain of custody, emerged as the first serious document-workflow infrastructure. In parallel, Luca Pacioli's 1494 codification of double-entry bookkeeping standardized the schema in which Italian merchants had already been recording activity for more than a century. He didn’t invent double-entry, but he did standardize it, and the standardization is what scaled.
What print actually did, over the long run, was force the world to build the first serious infrastructure around documents. The property under pressure was trust, and chanceries and shared schemas were the response.
Crisis #4: too much paper for any human to read (c. 1945)
The mid-twentieth-century bureaucratic explosion (wartime intelligence, postwar regulation, modern corporate management) pushed paper volumes past the point where any individual could keep up.
Vannevar Bush's "As We May Think," published in The Atlantic in 1945, describes a device called the Memex: a desk that would hold an entire personal library on microfilm and let its owner build associative trails between documents. We didn't get the Memex. We got the filesystem, the database, the hyperlink, and eventually the search engine. Each is a different cut at the same problem.

None of these technologies replaced the document; they wrapped it. The document remained the unit of meaning, and the new layer became the unit of retrieval. The property under pressure was now navigable, and indexing (eventually full-text and link-based) was the response.
Crisis #5: the agents arrive (now)
Every prior crisis was about humans failing to keep up with the volume of records. This one is different.
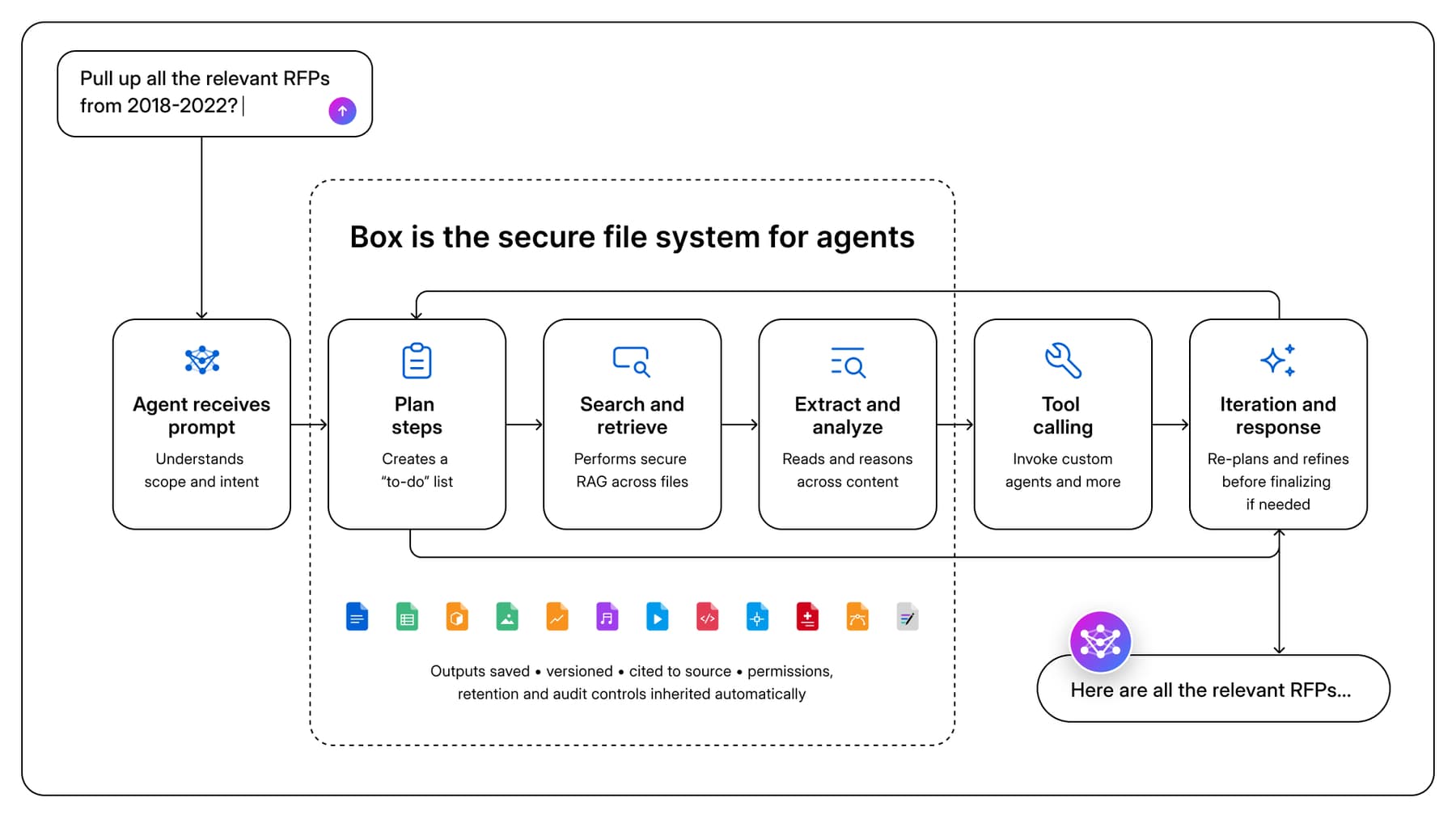
The volume of records hasn't suddenly exploded, but the volume of reads has. An enterprise that previously had one analyst skim a contract now has a fleet of agents reading every contract, on every query, on behalf of every user, in parallel, twenty-four hours a day.
This shift is real, and worth taking seriously on its own terms. Agents have already changed what's economically reasonable to ask of an enterprise's content. Workflows that used to require a team of humans skimming PDFs are now routine. Questions that used to be unanswerable, because the relevant material was spread across hundreds of documents, are now answerable in seconds. The retrieval layer is being reinvented in front of us: chat, multi-step planning, dynamic synthesis, semantic search over embeddings rather than filenames. This isn’t the same kind of change as moving from tape to disk. At the interface layer, it's the most significant change since Bush's Memex was a sketch on paper.
What isn't changing is the layer below the interface. A reading rate this high stresses different properties than any of the previous crises did. Storage is solved. Retrieval is largely solved. What now strains under agent-scale reading is identity, provenance, access control, version discipline, and structure. The same properties on that 4,300-year-old clay tablet, only now under a load no human archive ever faced.
That is why the phrase "file system for AI" is more literal than it might sound at first. AI needs more than access to content. It needs a governed system of record for content: identity, permissions, provenance, versions, retention, classification, and enough structure for both humans and machines to know what they’re looking at. Without that layer, agents are fluent readers standing on top of an ungoverned archive.
AI needs more than access to content. It needs a governed system of record for content: identity, permissions, provenance, versions, retention, classification, and enough structure for both humans and machines to know what they’re looking at.
The mistakes that come out of agent deployments make this concrete. An agent answers a question using data the asker wasn't allowed to see, because the access-control story for a chat-mediated query is harder than for a file open. An agent summarizes a stale version of a contract, because nobody told it which version was canonical. An agent confidently cites a number from a deck that was never meant to be a source of truth, because the deck had a clean, retrieval-friendly title. An agent runs against a folder of 40,000 documents and produces an output nobody can later trace to a specific source.
None of these are model failures. They're content failures. And they're failures of exactly the properties that every previous archival civilization spent centuries getting right.
The hard enterprise AI question is no longer just "can the model answer?" Increasingly, it can. The harder question is "can the institution stand behind the answer?" Can it prove which sources were used, whether the user was allowed to see them, whether they were current, whether they were authoritative, and whether the answer can be audited later?
Those aren’t model capabilities. They’re content-platform capabilities.
This is the part of the AI stack that has been most chronically under-invested in. The model layer gets a frontier release every quarter. Agent frameworks arrive every week. The substrate underneath, the part that decides whether the answer the agent produces is defensible, has barely moved.


What only an inspectable record can do
Every property I've listed so far (addressability, provenance, access control, versioning, structure) can be argued about. You could imagine some agent registry, some graph database, some memory layer doing parts of the work, some of the time. The debate at that level is mostly an architecture debate, and architectures get redesigned every decade.
There's one property I think isn't negotiable, and it's the one almost never written about in the AI-replacing-files literature. Knowledge an institution depends on has to be legible to humans.
Humans won't read most of it most of the time. The agents will. But the moment anything goes wrong, a person must be able to walk back to the source, in human language, and check.
This isn’t a sentimental claim; it's the property that lets institutions correct themselves. A contract that was misinterpreted can be re-read. A regulation that was misapplied can be re-cited. A study that turned out to be flawed can be re-examined. The entire architecture of accountability (courts, audits, peer review, journalism, the appellate system) rests on the assumption that the knowledge an institution acts on can be inspected by a human, in its original form, after the fact. Strip away that property and you’ve removed the institution’s ability to repair itself.
Three implications follow.
First, you can't disagree with model weights. Societies move forward because someone reads what an earlier generation wrote down and concludes that it was wrong. Galileo could disagree with Aristotle because there was an Aristotle text to disagree with. Scientific revolutions, legal reform, a serious newspaper’s corrections page: all of them depend on a fixed artifact that can be quoted, contested, and superseded. A model's "view" of a topic isn't that kind of fixed artifact. You can't mark it up. You can't supersede it cleanly. You can only retrain, which is closer to forgetting than to revising.
Second, model weights are a powerful reader, not a record. They're a compression of training data and fine-tuning signal into a statistical machine that produces fluent, often useful output. That’s a remarkable thing, and the value it unlocks for enterprises is real. But you can't point a regulator at a tensor and say, "this is what we believed at the time of the decision." You can't show a customer the paragraph that explains why their claim was denied if the answer was synthesized on the fly. You can't onboard a new employee by telling them "go read what we know" if what you know is encoded in a process that gives a slightly different answer every time you query it. The model is a reader of the record. The record still has to exist somewhere.
Third, the record has to outlive the reader. Institutional records are measured in decades. A contract signed today must be readable in 2055. A medical record must be intelligible to a clinician in 2080. A regulator's archived audit must be inspectable in 2090. No model has ever been maintained over those horizons, and there's no plausible path to one. The substrate of important knowledge has to outlive the model that reads it, for the same reason it has had to outlive every previous reader: papyrus, printer, microfiche, hard disk. The unit that survives across substrate changes is the document. The reader is replaceable. The record is not.
The function a record performs is the load-bearing property of how a literate society holds itself together: being a thing a human can read, verify, point to, correct, supersede, and rely on a century from now. Agents don’t relieve that requirement. They intensify it.
In the Norwegian mountain
You can see this argument being taken seriously, in the physical world, by people who have no commercial reason to bluff. On the Arctic archipelago of Svalbard, a few kilometers outside Longyearbyen, two preservation facilities sit buried inside mountains in permafrost.
One is the Global Seed Vault. Duplicate samples of nearly every important crop on earth, sealed away in cold rock so that agriculture can be rebooted if something goes catastrophically wrong.
The other is the Arctic World Archive, run by the Norwegian company Piql. A snapshot of GitHub's open-source repositories now sits inside it, etched onto archival film, alongside contributions from national libraries, cultural institutions, and private depositors. Some of my own old commits are on that film, which is probably the closest I'll ever come to being one of those Mesopotamian scribes. The archive is designed to last a thousand years without electricity, without a network, without a model to interpret it.
Both vaults are answers to the same question; What survives once the current generation of readers is gone?
In both cases the answer is the same; A physical record, in a form a human can decode directly, deliberately decoupled from whatever software happens to be in fashion when it’s created. The most paranoid archivists in the world independently arrived at the architecture this essay has been describing. They aren't being nostalgic. They're being careful.
Why the file keeps winning
Each of the historical crises produced confident predictions that the document was about to be replaced. The scroll would replace the tablet. The codex would replace the scroll. The web would replace the database. The chat interface would replace the file.
In every case, the thing one layer up did get invented and was important. But in every case, the underlying artifact also stuck around. We keep rediscovering the same lesson every couple of millennia: a record useful to a society of strangers, strangers separated by distance, time, mistrust, and regulation, has to be a thing. A conversation can't do those jobs. A model, on its own, can't do those jobs. Only an artifact a human can hold open and read can.
It would be easy to read this as a defense of the past against the future. It isn't. Agents are the most powerful readers we've ever built, and they’ll change what reading is for, how knowledge work is done, which questions are worth asking, and what the unit of effort looks like for a knowledge worker.
Agents are the most powerful readers we've ever built, and they’ll change what reading is for, how knowledge work is done, which questions are worth asking, and what the unit of effort looks like for a knowledge worker.
The file will survive that change. The question worth asking is whether the substrate underneath the agents, the part that handles identity, provenance, access control, versioning, and structure, is disciplined enough to make the agents defensible. Whether the answers they produce are things an institution can stand behind, audit, point a regulator at, and supersede when they turn out to be wrong.
That's an engineering problem, and it's one of the most important problems in the AI stack right now. The model layer is contested by everyone. The agent layer is contested by everyone. The governed content layer underneath them is still being recognized for what it is: the accountability layer for enterprise AI.
The winning AI companies will be the ones that make the record usable by machines without making it unaccountable to humans.
That’s the real future of the file. Forget the folder icon and the desktop metaphor. Think instead of the governed, inspectable, intelligent substrate beneath enterprise AI. The file is older than the alphabet. Agents aren’t the exception to its survival. They’re the strongest argument it has ever had.