A few months ago, I worked on improving performance of our 'full' indexer. I feel that the improvement was significant enough to share the story. Full indexer is Box's process to create the search index from scratch, reading all of our documents from an hbase table and inserting the documents in a Solr index.
We shard our indexed documents based on the id, and the same document id is also used as the key the in hbase table. Our Solr sharding formula is id % number_of_shards. A mapreduce job scans the hbase table, computes the destination shard of each file by the above sharding formula and inserts each document in the corresponding solr shard. Here is a schematic diagram of the initial model which has served us well for the past few years:
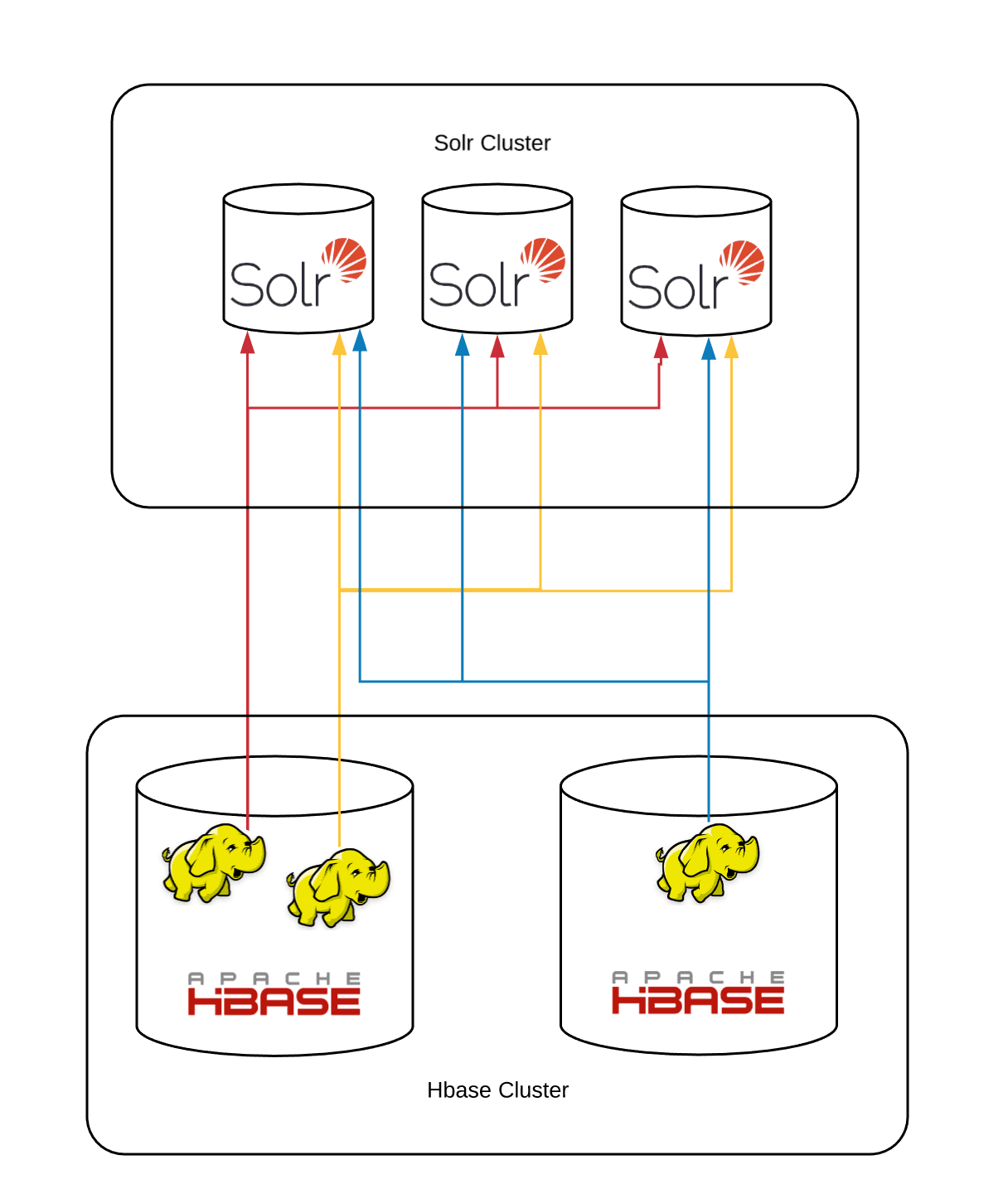
All mapreduce jobs talk to all shards, since data for each shard is distributed across all hbase regions. The job is a map only job, there is no reduce job. The hbase table scanning as well as the update requests are all being done in the mappers.
Within each mapper, there is a shared queue of batched jobs; and a shared pool of http clients which take a job from the queue and send it to the respective shard. Each individual document is not directly inserted into the queue. Rather, documents which need to be indexed on the same shard are batched together before inserting in the queue (current default is 10). The queue is bounded and when it is full then the document producer has to wait before scanning more rows.

If all Solr shards continue to ingest documents at a uniform and consistent speed* then this system works at a stable speed. However, every now and then, Solr will flush in-memory structures to file and this I/O can cause some indexing operations to temporarily slow down. During this stage, the cluster does not serve queries so that is not a concern.
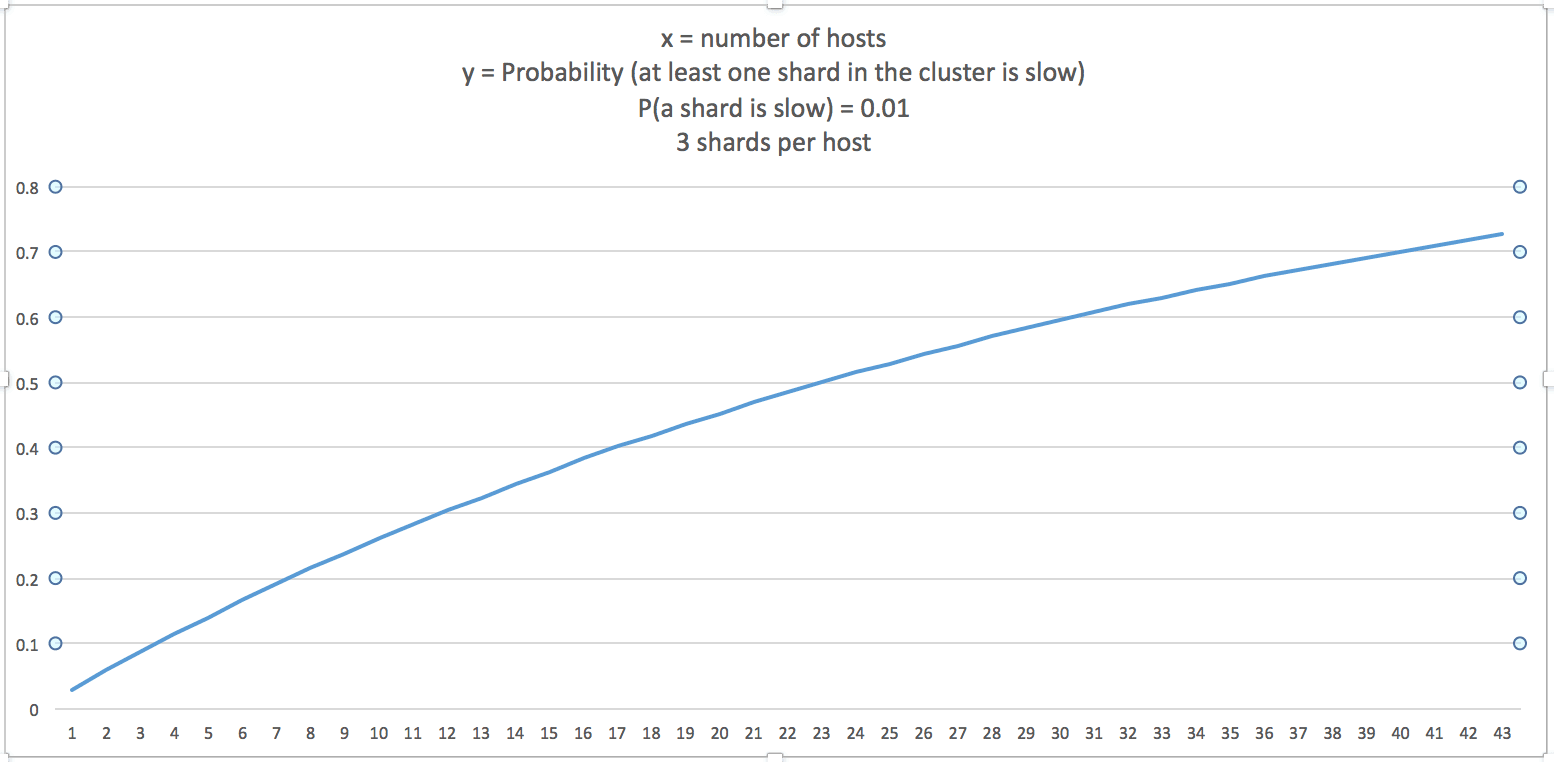
If the total number of shards is n, and the probability of intermittent slow indexing rate for a given shard is p, then:
P(at least one of n shards is slow) = P(exactly one shard is slow) + P (exactly two shards are slow) + ... + P (all n shards are slow)
OR
P(at least one shard is slow) = 1 - P (no shard is slow)
P(at least 1 of n shards is slow) = 1 - (1-p)ⁿ
If we assume that for a given time interval p = 0.01, here is the chart for P(at least one shard in the cluster is slow):
This means that to have good indexing performance with more shards, we needed to isolate the bottlenecks of one shard from affecting the indexing of other shards. My first attempt was to increase the pool of workers such that if a few workers are stuck at one shard due to it being slow, then the rest of the workers can continue processing the queue. This helped but still there was a chance for all, or many, of the workers to be stuck when they pick jobs, which go to intermittently slow shard(s). In this situation, the document producer thread will not be creating new documents as the queue is full, and all the workers are not able to progress because they are waiting for their slow jobs to finish. In my second attempt, I created separate queues and workers for each shard (on each mapper), this ensured that if some shards are slow, then the rest of the shards don't have to sit idle as their workers will continue to read the jobs from their queues and send them for indexing. Eventually, the shards which were catching their breath will start indexing faster again, while some other shards may start responding slowly and so on. This drastically improved the total flow of the system.

This is the chart with 39 hosts with the older concurrency model. The job crashed after running for three days. Even before the crash its performance was inconsistent; Also average indexing speed of a shard was lower than what we used to see with fewer total shards.

This is the same job on the same set of hosts with new concurrency model, where it performed much better and more consistently:

The unit on the y axis is number of reads per second. It has more than doubled. Box has almost 50 Billion documents** and with the improvement the full-indexer is able to finish this indexing phase in less than two days.
However, this new model also has its drawbacks, for example:
- This model does not have communication between workers which are targeting the same shard. So, when a shard is responding slowly, workers from other parallel running mappers continue to send it requests (and failing, and then retrying) even though one or more workers (in other mappers) have already identified that the shard is slow.
- Since each mapper is allocating a fixed length queue for each shard, the design will not scale beyond a certain number of shard; because the memory requirements for the queues will exceed the heapsize of the mapper.
A more scalable model will involve a queue between the mappers and the Solr shards. And there should be shard-specific clients, which can possibly be run on the shard's host, which will read the shard's documents from the queue and send to Solr for indexing (either through the REST API or SolrJ).
* Hbase table scan and document producer is not our bottleneck hence I only mention Solr indexing performance here.
** This statistic is a few months old.