Consistency is a key concept in data storage: it describes when changes committed to a system are visible to all participants. Classic transactional databases employ various levels of consistency, but the golden standard is that after a transaction commits, the changes are guaranteed to be visible to all participants. But as per the CAP theorem, such systems sacrifice availability in the presence of network partition in order to guarantee consistency.

Amazon's S3 takes a different approach where it ensures high availability even in the presence of network partition, hence adopting an eventual consistency model. Eventual consistency relaxes the rules a bit, allowing a time lag between the point the data is committed to storage and the point where it is visible to all others. But this can lead to issues during various operations especially when using the list functionality. If an object is added to S3 and immediately list() is called on its parent path, the object may not be visible. Similarly a deleted object can still show up when list() is called after the delete operation. This could lead to potential data loss scenarios particularly when S3 is used as the source of truth and not just as a backup or intermediate store.
Why Eventual Consistency impacts Box
At Box, our Analytics Infrastructure relies on S3 as the source of truth in the cloud. Analytics data generated by various systems is first written to on-prem Kafka topics. The S3 committers then consume from these topics and write to a source bucket in S3, as shown in the figure below. Due to the nature of the Kafka pipeline, it is possible for the same message to be consumed by the committers more than once, leading to duplicates in the source S3 bucket. To remediate this issue, we run a de-duplication job. At its core, this is a MapReduce task which periodically picks up the objects from source S3 bucket, de-duplicates them against a target S3 bucket, and writes all the distinct new object to the target bucket. Hive tables are created on top of the data in the target S3 bucket, which is then used for analytics and reporting purposes. An ETL process also runs on top of this data to process and move it to Redshift which then powers various dashboards.

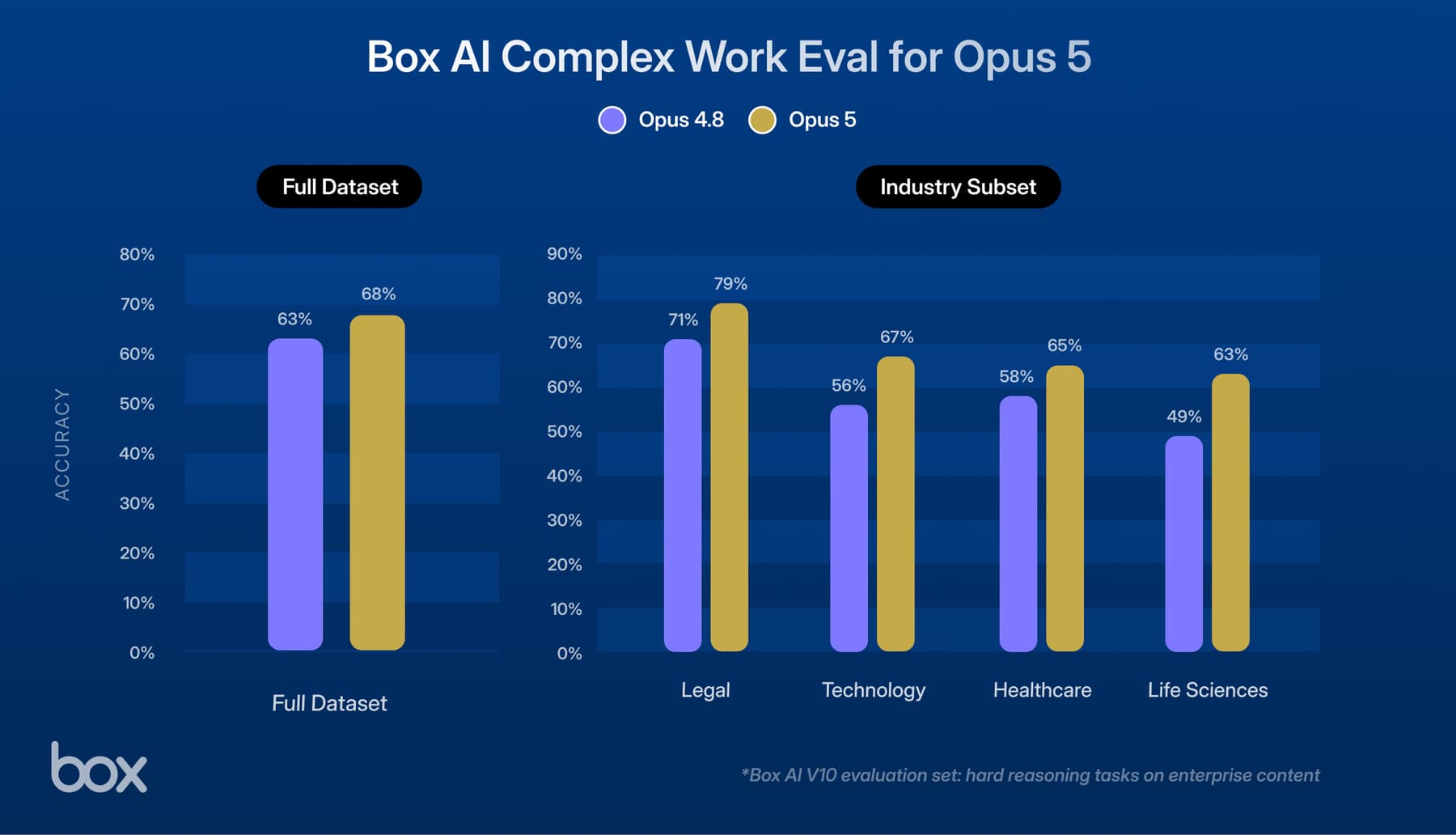
Both the Dedupe and the ETL process rely on list operation of S3 to find and move objects. In the face of eventual consistency, the list operation can leave behind objects which will then never be moved to the target bucket in S3 and hence be lost for ever. Similarly ETL can fail to process and move data to RedShift if list operations are not strongly consistent. Given the rate at which we write to S3, eventual consistency is not just a theoretical phenomenon. We observe it every day. Below, a graph from Wavefront shows potential consistency issues observed over a week. Sometimes more than 2000 eventual consistency incidents are observed during a single day's dedupe run.

Existing tools to solve Eventual Consistency
When we first started building our analytics pipeline, we came across a couple of tools which helps address this problem with eventual consistency of S3. After all, there are many who are plagued by this issue.
Netflix S3mper:
A few years back, Netflix ran into a similar problem with eventual consistency of S3 and decided to build S3mper. It is a java-agent based system that attempts to address this issue by hijacking the filesystem calls to S3 and validating them using a DynamoDB based metastore. It detects consistency issues and attempts to recover from them. Unfortunately for us, it also had the following issues:
- S3mper did not address consistency issues in the presence of delete and rename operations.
- Java Agents can sometimes be unpredictable in terms of intercepting the file-system calls. If the interception fails there is no way to find out. This can lead to silent consistency issues.
For more details on S3mper please refer to the Netflix blog.
EMR Consistent View:
Elastic MapReduce is a product by Amazon which provides a Consistent View option that uses a DynamoDB metastore to identify and resolve consistency issues with S3. This approach is better than the java-agent based S3mper in terms of dependability and completeness. But since we were already using Qubole (alternative product to EMR) as our compute engine, it was not feasible for us to switch to EMR. Moreover, consistent view would have additional cost implications for Box.
So we decided to build Snitch, to help us detect and recover from consistency issues as well as collect metrics to efficiently monitor and alert in case of such events.
Snitch: Virtually Consistent FileSystem
Snitch is a filesystem which extends the S3AFileSystem and overrides the core operations to additionally maintain a consistent meta-store in DynamoDB. At its core it is quite similar to the approach taken by S3mper and EMR. When a new object is added to S3 we record this fact in DynamoDB. During list operations we compare the object list returned by S3 to that in DynamoDB. If an object is present in DynamoDB but not in S3 then it is a potential consistency issue. In this case we attempt to refetch the list from S3 after some exponential backoff, hoping eventual consistency to be attained. If we are unable to achieve consistency even after a certain number of retries we raise an alert.
In case of renames and deletes, we mark the deleted objects in the metastore. During a list operation these objects, which are marked deleted in the metastore, are removed from the S3 list by Snitch. In this way we are able to guard against eventual consistency of S3, attempting to recover when possible. Since Snitch overrides the underlying filesystem operations directly, we are guaranteed to perform the additional consistency checks and book-keeping. This leads to higher reliability as compared to S3mper.

Performance Enhancements
In order to ensure freshness of analytics data and meet delivery SLAs, the analytics pipeline has to execute operations in a highly performant way while moving petabytes of data. As a result Snitch needs to execute filesystem operations without adding any overhead latency due to DynamoDb operations. To ensure this, we had to make some key performance improvements:
FileSystem Operations
One way to mask the overhead of the metadata operations, was to make the underlying filesystem operation faster. The default S3AFileSystem is great for performing single writes or moves on S3. But when it comes to workloads like Dedupe which moves millions of S3 objects across different S3 locations, it simply doesn't fit the bill. Hence Snitch reimplements some of the write functionalities by leveraging the S3Client batch write API's directly and internally parallelizing disjoint operations where possible. This enables us to truly leverage the available S3 throughput and also reduce network traffic by performing fewer calls.
DynamoDb Metastore
When we first deployed Snitch in production, our main performance bottleneck was due to throttling from DynamoDb itself. Interestingly, this was not as a result of the provisioned read and write capacity on DynamoDb, but due to hot-spotting of partitions/shards. DynamoDb uniformly divides the provisioned capacity amongst all the underlying partitions. If a large number of reads/writes are directed to a single partition, it can exceed its provisioned capacity and cause throttling even though the overall capacity hasn't been exceeded. Since all objects under the same path have the same key in the DynamoDb table, they are all directed to the same partition. Hence paths with large number of objects lead to hot-spotting on the corresponding partition. To address this problem, we add a salting prefix to the table key in DynamoDB based on a composite hash of the path and the object identifier itself. In this way object keys with the same parent path end up on different partitions thereby distributing the throughput more uniformly and reduce throttling at the partition level.
After the above mentioned enhancements to Snitch we saw an order of magnitude improvement in file-system operations as compared to S3AFileSystem.

Deployment in Production
As seen in the system diagram earlier, there are multiple components that interact with S3 directly or in-directly (via Hive). Some of them are under our control as they are services implemented by us (such as dedupe), but the rest of them are not (such as Hive, Qubole etc.) All of these systems need to use Snitch in order for this to actually work. If any component talks to S3 bypassing Snitch, it can corrupt our metastore in DynamoDb and lead to fake eventual consistency issues. To avoid this, we need to make Snitch omnipresent. We achieve this with the help of core-site.xml. Any component interacting with S3 in a hadoop eco-system always uses a set of hadoop configuration files. The master of all these files is the core-site.xml which dictates, amongst other things, which filesystem to use for hadoop operations. We configure it to be Snitch. The core-site.xml is then propagated to all on-prem clusters running Dedupe, hive-servers as well as EC2 instances spawned by Qubole to execute MapReduce jobs. Along with this the Snitch Jar is also placed in the hadoop classpath so that the Snitch filesystem can be instantiated and used by all hadoop operations.
Results
Snitch had been consistency aware for more than a year now. It has successfully averted numerous data loss situations when S3 was in-consistent. Below graph shows occurrences of successful recovery from eventual consistency by Snitch over a one week period.