At Box, we manage several large scale Kubernetes clusters and heavily rely on real-time metrics to monitor them. In addition to metrics coming from the control plane (for example from kube-state-metrics), all applications running in Kubernetes also emit metrics. We define expected behavior using alerts. If the metric deviates from the expected behavior, alerts create notifications.
There are two ways a metric can deviate from expected behavior. The obvious first one is that the value of the metric is an anomaly or an outlier according to the alert definition. The second is that the metric stops generating new data. In the second case, the alert may or may not fire. Different alerting solutions have different approaches to handling delayed or missing data.
We have discovered that the lack of incoming metric values is as important an indicator as incorrect values, and many of our alerts were not formulated correctly to deal with lack of data. In this blog post, we would like to share our experience and lessons in how to handle delayed or missing metrics in alerts. At Box, we use Wavefront for metric storage, monitoring and processing. Later on, we'll also deep dive into our solution and design considerations using Wavefront.
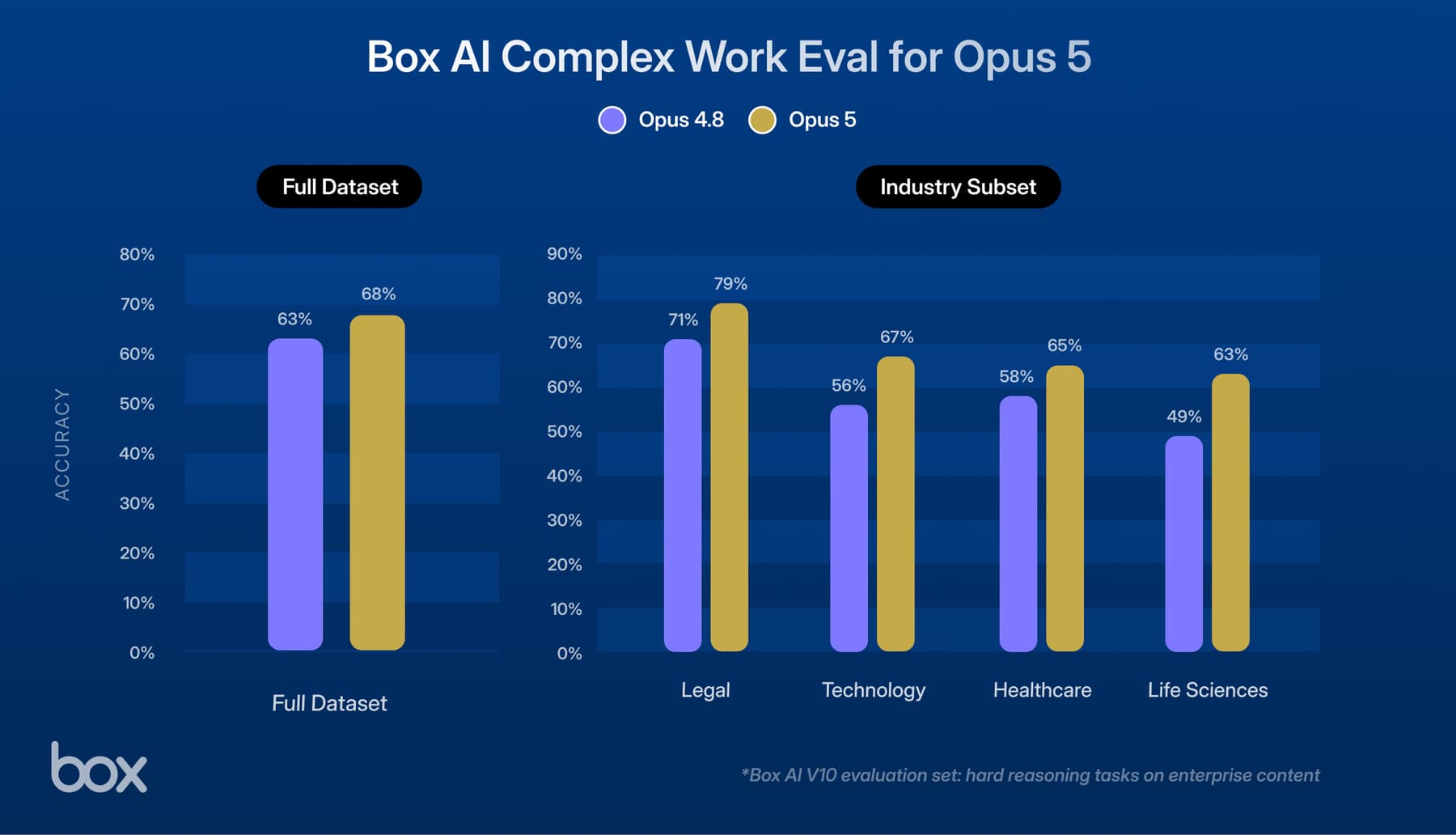
As an example, let’s consider the kube_pod_status_phase metric emitted by kube-state-metrics which runs in a pod as part of a Kubernetes cluster. We want to be notified if less than 60% of our pods are in Running phase. The alert condition in pseudo-code looks like this.
("kube_pod_status_phase",phase=Running) / ("kube_pod_status_phase") < 0.6
Quite straight-forward: If the ratio of “Running” pods to all pods becomes less than 60%, a notification will be sent.
The problem here is that the condition will NOT evaluate as "false" if there is no incoming data. Consider your entire Kubernetes cluster being down due to a catastrophic issue. In that case, the source of this metric will also be down and no new data will be generated. This is a situation where you definitely want to get notified, but this condition alone will not do so. Unfortunately, this is not a hypothetical example for us, as we have experienced this exact scenario and that triggered a critical analysis of all our alert formulation.
Checking for delayed values in alerts can also detect metric changes that make the alerts obsolete. For example, there have been corrected typos and name changes to metrics in the kube-state-metrics project. Once you deploy the new version of kube-state-metrics, your existing alerts that used the old metric names are not operational anymore. If you had formulated your alerts to notify in case of disappearing data, you could quickly fix all your monitoring gaps after a change to sources of metrics.
Once you recognize that you need to detect missing data in your alerts, how do you do it? Various monitoring systems like Influxdata, Prometheus, DataDog and Wavefront handle delayed or missing data slightly differently, but in all of them, the user needs to explicitly enable notifications and determine a timeframe to allow reasonable lag before notifying. Influxdata has a deadman switch, Prometheus has the absent function, and in DataDog you can opt in to notify on lack of data. For Wavefront we will have a more detailed explanation of our solution later on.
The delay time to notify in the case of missing metrics is an important parameter to consider. It may be different from the notification delay for abnormal values. (For example, at the time of this writing, DataDog enforces that the missing data window to be longer than the delay to notify for abnormal values). Managing delayed values is a well-known challenge in robust alerting. While we want to react as fast as possible to issues, we also want to minimize alert-fatigue with false positives. For example, if your metrics pipeline is unstable at times and every glitch is causing a 20 minute delay in metrics, the no data notifications should not cause alert storms to application owners.
Wavefront also recognizes that the missing metrics can be a problem in defining robust alerts. They suggest using mcount function to detect suspended data. Recently a NO_DATA state has also been introduced for alerts but is it not widely applicable yet. On the other hand, our experience and use cases have driven us to a different solution that can also be applicable to other Wavefront users.
In our considerations, wrapping the alert condition with a default() function has been the most effective way of dealing with missing data.
The default function documentation is as follows:
For our previous example above, the improved new alert condition looks like:
default(4d, 15m, 1, ts("kube_pod_status_phase",phase=Running) / ts("kube_pod_status_phase") < 0.6)
timeWindow :
How many days the default value will be filled? Due to performance considerations, this is not set to infinity, instead we have selected 4 days. This number must be longer than a weekend. With our on-call rotation changing at the start of the week, we want an alert to continue to fire on Monday if it has started to fill default values on the previous Friday.
delayTime:
After several iterations, we ended up allowing 15 minutes before firing notifications due to suspended data. Given the glitches in our metrics pipeline, 15 minutes was enough to avoid a majority of false positive notifications.
defaultValue:
The fill value should be 1. By definition a True output from the alert condition evaluation causes alert notification. By filling 1 for missing values, the alert gets triggered.
expression:
Formulation of your original alert condition in wavefront query language.
We hope as a result of this post, you see the value of detecting delayed or missing data in your alerts. Surely, there has been numerous issues in our systems that were caught at an early stage thanks to the alerts detecting missing data.