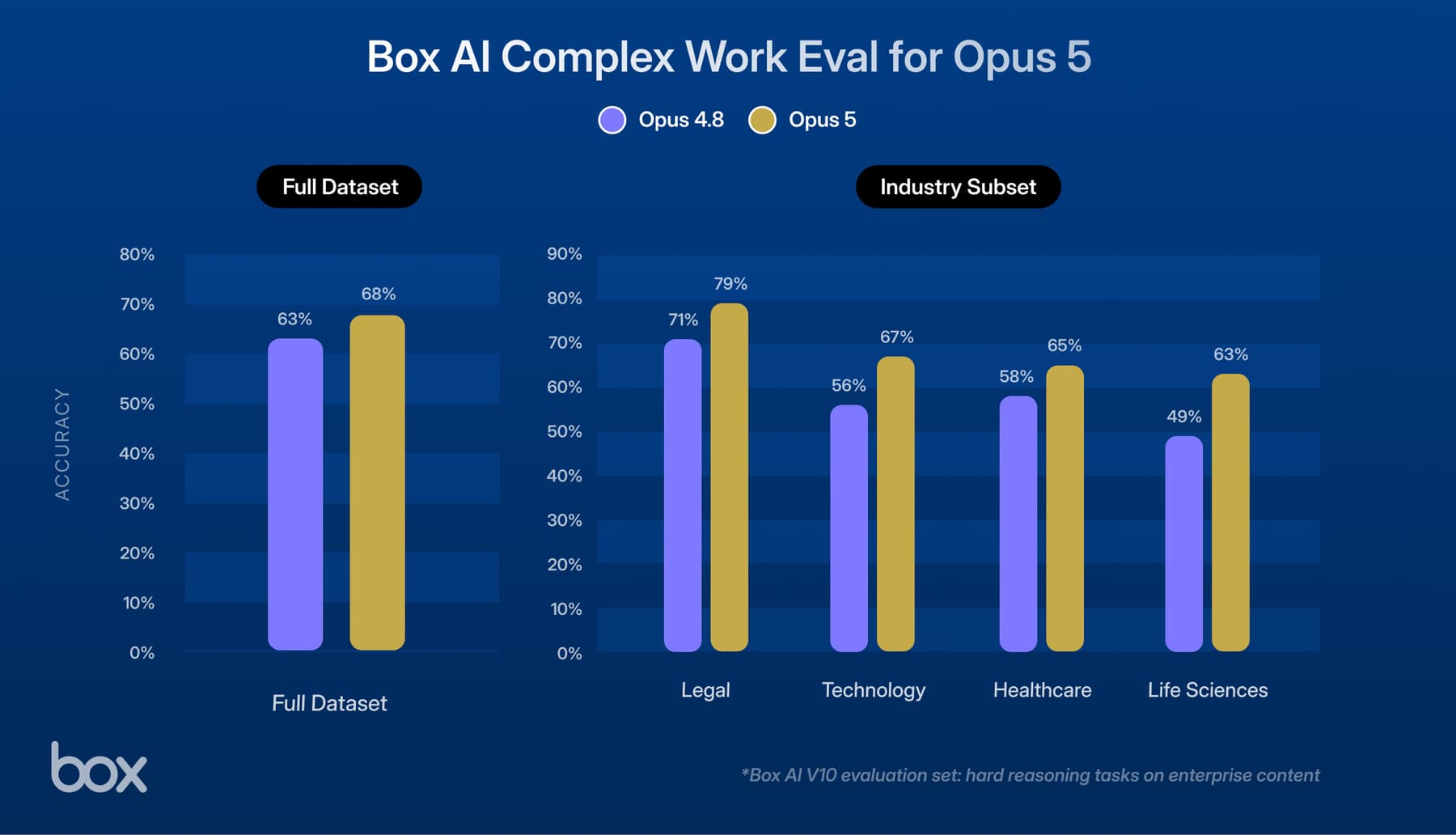
![[Demo] Box + Pinecone](/_next/image?url=https%3A%2F%2Fbackend.blog.box.com%2Fsites%2Fblog%2Ffiles%2Fstyles%2F2200xauto%2Fpublic%2F2025-11%2F35.png%3Fitok%3DxwOCis0-&w=1800&q=75)
Continuing on Box’s AI journey, I’m excited to launch this tutorial and integration with Pinecone. For those new to the LLM (large language model), RAG (retrieval augmented generation), and generative AI space, Pinecone is a managed, cloud-native vector database. It provides a streamlined API with no infrastructure hassles that provides long-term memory for high-performance AI applications. Connecting Box and Pinecone allows you to customize and manage custom vector embeddings that a LLM can use to give you more relevant answers. As you feed it additional context from your own content silo, it gets information it wouldn’t otherwise have. For example, the additional data could be used in a question-and-answering bot, and that’s what we are going to look at building today.
RAG concept overview
Before getting into the demo, let’s review some key RAG concepts that will help you understand why this is so cool.
What is a vector database?
As mentioned above, Pinecone is a cloud-based vector database, but what exactly does that mean? Simply put, it is a way to store and retrieve representations of your data, called embeddings, so that you can find results that are similar in meaning rather than literally the same.
What are embeddings?
Embeddings are a mathematical representation of the meaning of your content. They are generated by taking the input data, splitting or chunking it, and using an embeddings model (which some LLMs provide) to output a string of float number values, for example, ([0.3,0.4,0.1,1.8,1.1…]). You can think of these values as mapping ideas as points in space. There are lots of different embedding models that are trained on different data– some are specialized for specific use cases.
In the graphic below, you can see many dots in a three dimensional space. Each dot represents a noun in this example, but in Box’s case it would represent pieces of content. If the database is everything, and each dot a specific thing, similar things are grouped together. Cat is very close to kitten, but they are still different points. Banana and dog are very far apart.

In order to use these associated data later, like in a question-and-answering bot, you need to store them somewhere. Enter Pinecone. As shown in the store column below, the embeddings are stored in a vector database, alongside other relevant metadata like file name, to be retrieved via search later on.

How does all this work together?
Let’s say a user wants to ask a question about the content stored in a Box folder. Below, you can see a typical flow of how this would work.
The LLM doesn’t know what’s in your Box folder. It doesn’t have access. So you need to extract the pieces of information that match your question, then pass them to the LLM so it has the information it needs to generate an answer.
Previously made embeddings are stored in Pinecone and shown in the retrieve block. An input question is transformed into embeddings using the same embeddings models that transformed the content. Using Pinecone’s query functionality, subsections of the content (highlighted in blue) are relevant to the question are retrieved. The question and selected sections of content create the prompt that is sent to the LLM to answer the user’s question.

Demo
Now that you have a better understanding of how the pieces work, I will walk you through a demo on how to create and store embeddings in Pinecone for a specified Box folder. The demo also includes a query capability for you to send in questions and get answers via a third party LLM provider.
Prerequisites
- You need to have a Box folder created with a subset of data that you want to ask questions about. In my case, I threw in several different items — some related to Box and others not. This folder should be accessible by the user account that creates the Box application. Note the folder id in the URL bar. Place this in your config.py file.

- You need to have a Pinecone account. Sign up for a free starter plan and get an API key. Then, place the API key in your config.py file.
- This demo also uses OpenAI to respond to a user’s question. Sign up for OpenAI and get an API key. You will most likely need to attach billing information. Place the API key in your config.py file.
- You need to have python installed on your machine.
Create a Box custom application
Create an OAuth app in the Box Developer Console. Follow the below steps to do so.
- After going to the Box Developer Console, click Create a New App in the top right corner. Select Custom App, fill in the form, and then click Next.
- Select User Authentication (OAuth 2.0) and then click Create App.
- Scroll down to Redirect URIs and add the following redirect URI: http://127.0.0.1:5000/callback
- Check all boxes in application scopes.
- Click Save Changes.
- Note the Client ID and Client Secret. You will need these later in your config.py file.
Create a Pinecone index
Once you login to the Pinecone Console, you will see a button that says Create Index. If you click it, you will see the screen below. Give the index a name and type 1024 into the dimensions field. Leave everything else as default, and click Create Index.
Note — you can do this step programmatically via the Pinecone API, but I wanted to show off their super intuitive and swanky UI.

Once created, you will see the below. Make note of the index name, in my case pinecone-demo. You will add this to the config.py file.

Initialize code repository
Open a terminal or command prompt. Clone the code to your local machine.
git clone https://github.com/yourusername/box-pinecone-sample.git
cd box-pinecone-sampleCreate and activate a virtual environment
python3 -m venv venv
source venv/bin/activateInstall the dependencies
pip install -r requirements.txtCopy the sample_config.py file.
cp sample_config.py config.pyOpen the code in an editor of your choice. Update the credentials/Box folder ID with the information you noted down earlier. Save the file.
Warning — DO NOT input 0 as the folder id. This will attempt to index your entire Box account. Not only is this not recommended, it will exceed rate limits, cost lots of money, and probably fail to complete.

Creating and storing embeddings
Once you’ve completed all of the above, you’re ready to make some embeddings.
In the terminal or command prompt, run the following.
python main.pyThe first time you run the application, you will get a popup in the browser asking you to grant access to the application. This is the standard OAuth 2.0 process you’ve most likely seen before. Click Grant Access to Box.

If you see the window below, it was successful. The tokens for the connection are stored in a file in the project called .oauth.json. If you use the application every sixty days, the refresh token will continue to work. You can close this window and go back to the terminal.

You should see the script processing the files.

Once complete, you can visit the Pinecone console to see the embeddings that were made. The sample also attaches useful metadata, including a reference back to the file in Box, the plain text of the chunk of the document, etc. We can use this metadata for filtering responses later and for things like managing versions of document.

Querying the LLM
Now that the embeddings are created and stored, let’s show off sending in a question to a LLM and getting results. This part of the project needs to use a third party LLM, since Pinecone doesn’t have an API that can do this for us. The demo uses OpenAI.
In the terminal run the following code.
python query.pyEnter a question to ask about the content stored in Box. Since mine is mainly about the Box File Requests API, I will inquire about those endpoints.

The service will reply with an answer.

Enhancement ideas
While this initial demo is relatively bare-bones, there are several enhancements that could be made to make it more advanced.
- Currently, the sample code is run in an ad-hoc way. You could create a scheduled task or webhook service that runs based on updates to the Box folder. This would automate running the scripts. The script upserts the data, so running the main.py file will update any records.
- The query script is run via command line. A UI could be created for a user to interact with.
- You could add other Box authentication methods, like JWT or CCG.
- AI/ML models could be changed. Right now, the embeddings are made with the new Pinecone inference API, and the query script uses OpenAI as the LLM. Any or all of this could be changed to better fit your needs.
- Other configuration options, like the vector database dimensions, metric, chunk size, etc are all customizable, too.
- The main script processes all files in the specified Box folder that have a text layer. Box automatically creates a text representation for these files, and this text is what the script uses to create the embeddings. If the file does not have a text representation, this solution will not work. It also only works on files less than 500 MB. You could add in third party libraries that more fully flesh out the content of any and all content types based on your use case.
Resources
Pinecone vector database overview
Find more sample code, tutorials, and more information about the Box AI Platform API in our Box AI Developer Zone.
In order to use the Box AI Platform API endpoints, you must be an Enterprise Plus customer. You must have an application created in the developer console with the appropriate Box AI scope, and your Box instance must have Box AI enabled.
🦄 Want to engage with other Box Platform champions?
Join our Box Developer Community for support and knowledge sharing!