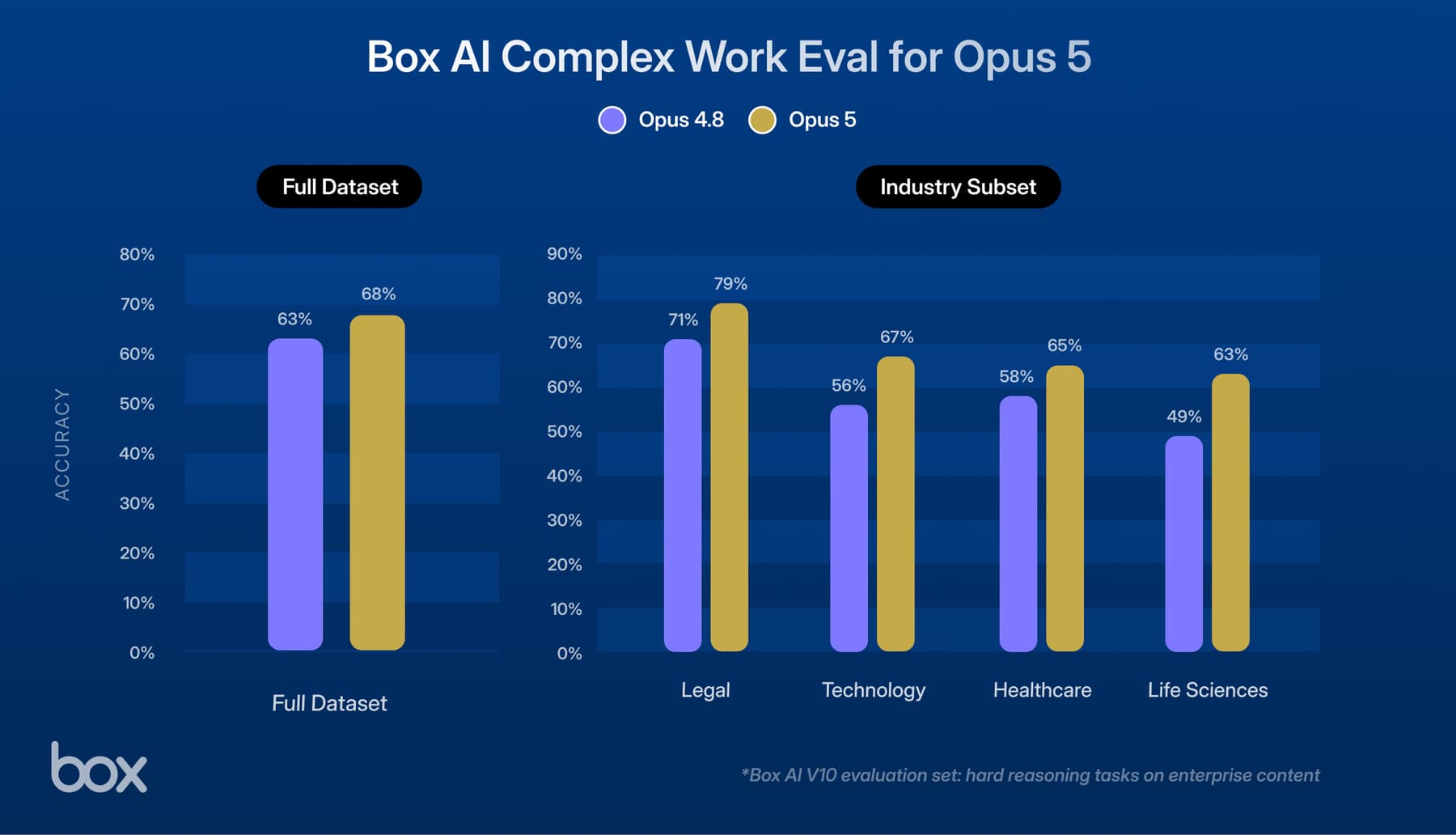
By now it's no secret that the amount of content that is being created and shared is increasing exponentially. To help extract value from all of that content, we introduced Box Skills, a framework that brings machine learning innovations to content stored in Box. For example, video intelligence, one of the initial Box Skills, provides transcription, topic detection, and facial recognition for individual videos. But that's just one file at a time.
We've also been developing a way to better understand your content at scale, to give you insight into the relationships between content and people. When users collaborate with each other to accomplish their work, these collaborations can be short-lived or last for months or longer. This activity implicitly forms a spontaneous social network within your enterprise. Unlike user-managed social networks, this spontaneity requires a real-time distributed graph that computes the network.
Enter Box Graph, our own machine learning model that actively interprets and then maps how your organization works. Box Graph understands the relationships between content and other content, content and people, and people-and-people. Graph continuously learns from everything you do in Box: from the shared links you generate, to the partners you collaborate with.
Below visual depicts user-to-user relations that are formed over a period within an enterprise.

From the graph we can gain various insights:
- users tend to cluster over work being done
- some clusters are isolated
- some users act as liaisons, bridging clusters
- some users are much more connected than others
One can use these valuable insights to serve relevant content to users and help them accomplish their job, help admins and team members to get a global picture of everything that is happening within their enterprise, and suggest relevant collaborators.
Implicit networks
Every day millions of users engage with content across various enterprises to accomplish their work. Each interaction contributes to a bigger picture of how work is being done in that organization. We can look at the user interactions (comments, views, modifications, etc) with the content to understand how users are collaborating, this forms the basis for the Box Graph.

In the above example:
- Joe works with File1, Sue is working on File2 and Bob is working on File3
- Once Sue starts interacting with File1 she forms a relation to Joe
- Similarly, as the work progresses more people can be part of the graph; in this case Bob has a relation to both Sue and Joe
This creates the implicit user-to-user graph, as derived from the explicit user-to-file graph
There can be many different types of these implicit networks that can exist across files, locations, tasks and other entities.
Building a scalable realtime graph
In our model, the thickness of the edge in the graph represents the strength of the edge, given by a score. If users are collaborating closely they have higher edge score. When recommending files, we recommend the top contributions of the top collaborators for a user (in the above example Sue and Bob are Joe top collaborators). To accomplish this, the graph should be able to:
- In realtime compute the collaboration scores across user to user (to determine top collaborators) from user to file interaction.
- Do these score computations in high throughput, low latency way, such that it scales to billions of edges (to handle Box traffic)
- List the top collaborators and top contributions in low latency way (to serve recommendations quickly)
We built a horizontally scalable, versioned graph system that can host realtime scoring formulas called Score Keeper Service (SKS) to maintain user to user and user to file relations. We asynchronously update the graph from user events using a high throughput , low latency, persistent queuing system called Message Queue Service (MQS is box built guaranteed delivery queue with isolation and QoS support).

SKS is built on top of HBase, with notion of channels (name space separation), each channel can host one or more graphs. Formula determines how graphs are updated with events and how to retrieve top edges for given vertex.
SKS stores scores in Scoring Table that allows for low latency updates of the edges. Ranking Table maintains the secondary index of score, to provide low latency retrieval of topN edges for given vertex.
Following diagram depicts the key design for scoring and ranking table.
Score Row Key
|<-sourceType-><-source-><-channel-><-targetType->|<------ target ------->|
|<------------------------------- 16 Byte hash ------------>|<-- 16 Byte hash--->|
Rank Row Key
|
|<--------------------------- 16 Byte hash ------------->|<-2x8 Byte Long->|<-8 Byte Long->|<-16 Byte hash ->|
Where SourceType is the source vertex type and TargetType is the target vertex type of the edge. Above design ensures that ScoreRowKey and RankRowKey will have same prefix, increases chances of collocating RankRows with ScoreRows, hashing reduces hot spotting and provides channel level separation of graphs.
Updating 4 billion edges per day

High throughput score updates of edges are accomplished by:
- Partitioned writes per enterprise: all writes to specific partition are serialized allowing us to do cross row transactions for given enterprise
- Using batch api all the way from client to the hbase: reduces number of calls
- Dedupping close events: reduces the number of writes to hbase when there is a spike in the events
- Accumulation at the formula level: combined with batching, accumulation at the formula level allows us to accumulate multiple changes to same edge and make one write to the backend

Time slicing allows us to look at snapshots of the graphs as they were at a given moment in time. With a simple count Formula and a snapshot per day, one can ask the graph questions like how many views happened in the past 7 days. Or much more complex questions like: show the top users I was collaborating a month ago on this project. Time slicing of the graph is accomplished by leveraging hbase versioning and ensuring KEEP_DELETED_CELLS is configured to true on HBase.
Realtime formulas
One of the key requirements for formulas to be realtime is that they are incremental in nature and could be represented as an accumulation function.
Recency vs Frequency
The underlying theory behind the Box Graph is our own version of collaborative filtering. In our version, we think of our users as described by a vector of file interactions. An entry of a user vector measures the strength of that user’s interaction with the corresponding file. We quantify that strength as a sum over all the user’s interactions with a file as depicted by below graph.

The sum is taken over all the observed user-events with that file (all of the times the user opens, edits, comments, shares, etc), t is the current time, wᵢ is the weight associated to the event (for example, to emphasize that editing signals a stronger relationship to a file than just opening it) and tᵢ is the time of the event.

The parameter λ lets us control the time-decay tradeoff between recency and frequency. When λ is 0, then the formula reduces to counting the number of interactions of the user with the file. When λ is very large (and negative), then only the most recent event will contribute anything meaningful to the resulting score. To be able to incrementally update the score in realtime, we use the LogSumExp trick.
Cosine similarity
Each user can be described by a vector with an entry for each file

To compute the strength of the relationship between any two users, we can use a common measurement of vector distance, cosine similarity.

Two users are considered closest collaborators if they have the same affinity scores for the same files, in which case their cosine similarity is 1. If they have never worked on any common files, then their cosine similarity is 0. This can be expressed as

Now, we can infer the strength of any two users by observing the file interactions, and the strength of that relationship naturally time-decays and updates as more events are observed.
In practice, we must decide how frequently to update all the scores. We can choose to update all the scores (user-file as well as user-user) on some intervals via a large batch computation, we can choose to update all the scores on each event, we can make some approximation, or we can use some combination of the these strategies. To update user length incrementally for each user file event along with LogSumExp we use LogDiffExp trick.

In order to capture the real-time nature of collaboration, we’ve chosen to update the scores on each event. Every time a user interacts with a file, that entry in the user vector changes, and that user’s relationship with every other user also changes. Because of the number of users Box customers have, that amount of per-event computation is not feasible. Instead, on each event, we come up with an approximation by updating the user-user scores for only a subset of the other users. Since most users have a very weak relationship to almost all other users, by judiciously choosing which scores to update, the result is a pretty good approximation of the full update. We store log value of the numerator and denominator of cosine similarity, and with few math simplifications we can incrementally update.
A/B testing
To enable A/B testing, we need to ensure that we can maintain multiple graphs with different formulas. Following depicts the setup needed for this. Primary queue can update graph with Formula A and secondary queue can update graphs with Formula B. This setup can also be used to warm up Formula B before releasing while Formula A is live.

Backtesting
There are a few choices that need to be made to implement this algorithm - we have to choose the decay rate (λ) the event weights (wᵢ) and decide how to implement our user-user update rule. We use both backtesting and A/B-testing to help us understand the impact of the parameters or algorithms. Backtesting allows us experiment with different formulas and different parameters. It gives us a mechanism to test formulas that might be much more complex than collaborative filtering and get a sense of how far behind other strategies our current choices might be.

One challenge specific to Box is that when we backtest how Graph could be used in various products to service files to users (for example, in Feed), we have to take file permissions into account - was the user allowed to see a specific file on the day we're backtesting? File permissions at Box are fairly complex, and far too large to be denormalized. To overcome this problem and scale backtesting out to many enterprise customers, we cache a minimal amount of historical data we need to derive permissions, and developed a scheme to "batch compute" permissions on top of testing results in order to have a more accurate view of how the product will perform.
Because it’s using offline data, we can never be sure that gains made in offline testing will hold up in the product, but it has proven to be directionally relevant. In contrast, A/B testing gives us much finer grained control over what we observe. We can deploy the system with different choices of parameters and measure how users interact with features built on top of the graph. This helps us understand which parameter values are working the best and which tests to run next.
People swarm together to accomplish their work, to capture this spontaneous nature we needed realtime graph. We created high throughput realtime Box Graph by using data structures optimized for low latency retrieval of top edges and updates of edges. Taking advantage of few math tricks and processing optimizations we created formulas for collaborative filtering allowing us to compute recommendations in realtime. With backtesting and A/B testing we are able to fine tune the formula parameters for various unique use cases at Box.