Anthropic recently released Claude Opus 4.5, their most intelligent model to date. It arrives not just with more knowledge, but with a fundamental change in how it processes information: the ability to assign an “effort” level. Today, we are excited to announce that this new model is available for Box customers in Box AI Studio and via the API, giving enterprises the power to align AI "effort" with the stakes of their business decisions.

Higher accuracy on advanced reasoning
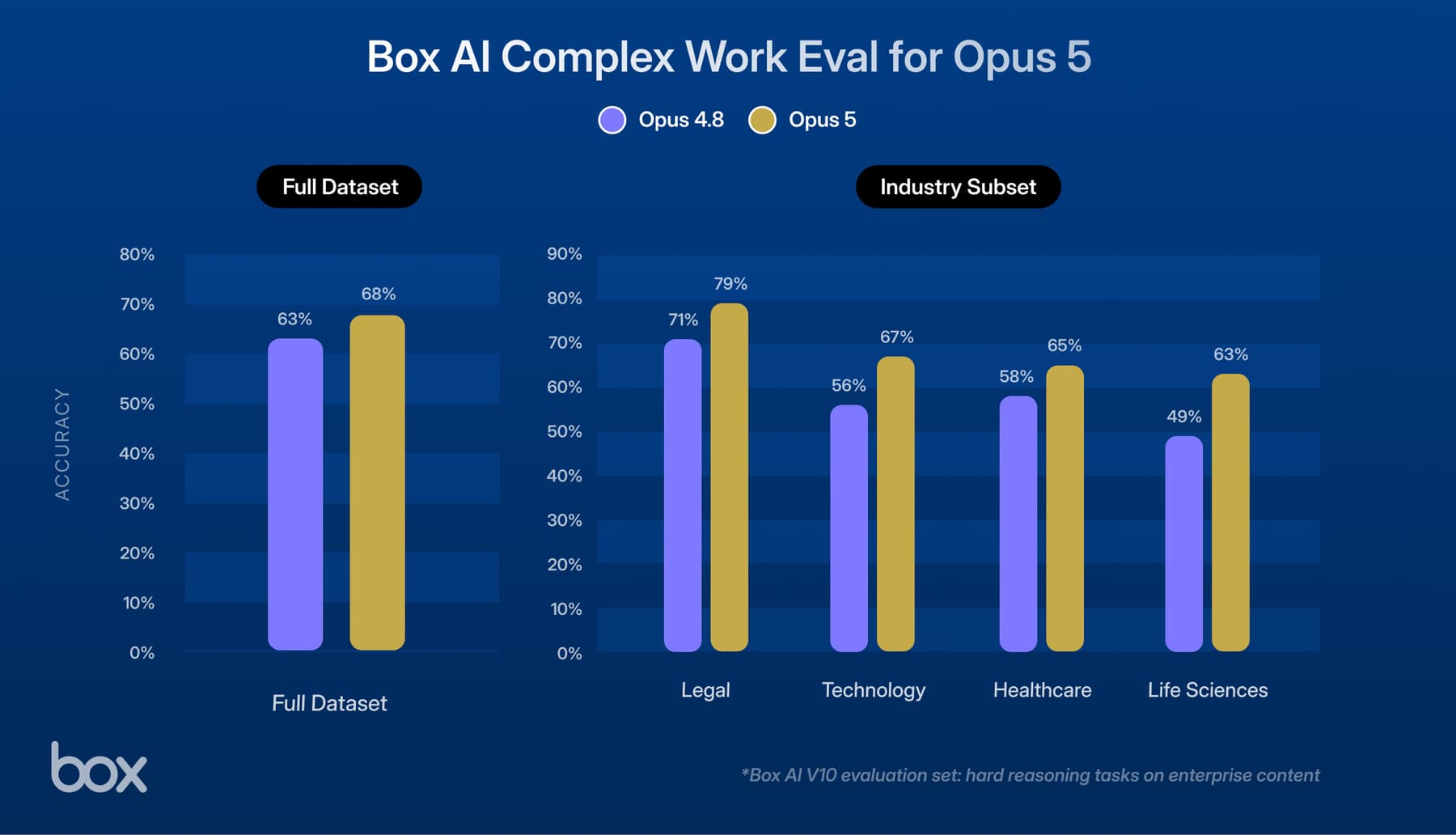
In our latest Box AI Eval, we conducted a rigorous comparison of Opus 4.5 running at both High and Medium effort levels against its predecessor, Opus 4.1. Our evaluation methodology focuses on "complex reasoning over documents"—tasks that require the AI to not just find a keyword, but to synthesize data from multiple sources, understand logical hierarchies, and produce a verified conclusion, in potentially various formats.
The results represent a step-change in capability:
- Claude Opus 4.5 (High Effort) achieved a score of 83%, showing the highest level of capability.
- Claude Opus 4.5 (Medium Effort) achieved a score of 79%, offering a balance of speed and performance.
- Claude Opus 4.1 achieved a score of 63%.
This indicates a more robust baseline for general reasoning tasks across diverse content types, ensuring users get reliable answers regardless of the complexity.
Understanding the "Effort" Parameter
The most significant innovation in Opus 4.5 is the "effort" parameter, which gives enterprise leaders control over how the model approaches a problem.
The “effort” setting controls how deeply the model reasons through a problem before responding.
- At High Effort, Claude Opus 4.5 engages in test-time compute. Before delivering an answer, the model generates internal chains of thought, exploring multiple analytical angles, verifying its own citations, and even "backtracking" if it detects a logical inconsistency in its reasoning. With this setting, the model uses more “tokens” to ensure that the answer is as accurate as possible.
- Why it matters: This mode simulates the behavior of a human subject-matter expert double-checking their work. It is designed for complex, high-stakes queries—such as analyzing a 50-page legal contract for "poison pill" clauses or cross-referencing clinical trial protocols—where the cost of an error is far higher than the cost of the compute.
- At medium effort, the model balances speed and depth, providing faster responses while still leveraging advanced reasoning capabilities—well-suited for routine queries or time-sensitive workflows. It outputs less “tokens” for the sake of generating a quicker answer.
- Why it matters: This creates an efficient baseline for routine queries, content summarization, and daily operational workflows. It allows enterprises to deploy advanced intelligence at scale without sacrificing the responsiveness users expect in real-time applications.
This flexibility allows enterprises to tailor AI performance to the task at hand: maximum intelligence when precision matters most, and efficient responsiveness for everyday use cases.

Transforming industry-specific workflows
While Opus 4.5 excels at general enterprise tasks, our testing showed it is particularly potent for industries that rely on dense, evolving, or creative knowledge bases. When running Claude Opus 4.5 with high effort, we saw major step ups in performance compared to Claude Opus 4.1:
- Education: Automating Grant Compliance (96% Accuracy) Managing research funding is a complex web of compliance. In our tests, Opus 4.5 at High Effort achieved 96% accuracy (up from 76%) in analyzing grant agreements against budget proposals.
- The Workflow: A university administrator can upload a dense federal grant agreement and a proposed curriculum budget. The model reasons through the specific definitions of "allowable costs" within the grant text, cross-references them with the budget line items, and flags discrepancies with near-perfect accuracy. This reduces audit risk and frees up staff to focus on research rather than administration.
- Energy: Safety-Critical Regulatory Analysis (89% Accuracy) In the energy sector, "hallucination" is a safety risk. We observed a significant jump in performance, with Opus 4.5 reaching 89% accuracy (up from 75%).
- The Workflow: Field engineers and safety officers can query complex technical specifications and new regulatory mandates (e.g., OSHA 2025 updates) to ensure operational plans are compliant. High Effort reasoning ensures the model captures the nuance of safety protocols, identifying potential conflicts between new regulations and legacy infrastructure documentation.
- Healthcare & Life Sciences: Precision in Clinical Guidelines (66% Accuracy) Comparing medical protocols requires a semantic understanding of clinical terminology. Opus 4.5 with High Effort achieved 66% accuracy (up from 42%), a massive leap in capability.
- The Workflow: Clinicians can ask precise comparative questions across complex medical documents—for example, "Compare the exclusion criteria in the 2024 vs. 2025 formularies." The model provides a synthesized answer that accurately cites specific changes, supporting critical patient care and compliance decisions with a verifiable audit trail.
Start using Claude Opus 4.5 today
The introduction of Claude Opus 4.5 empowers Box customers to tackle their most complex challenges with unprecedented depth. With the new effort parameter, you can now deploy High Effort reasoning, ensuring that your most critical, high-stakes workflows receive the rigorous analysis and precision they demand.
Claude Opus 4.5 is available today in Box AI Studio and via the Box AI APIs.