At Box, we’re used to choosing infrastructure that lasts. Databases. Storage systems. Compute layers. Hosting providers. Observability stacks. Processor choices.
If we’re doing our jobs well, the half-life of a major infrastructure decision is measured in years (ideally 5 to 10). This is a reflection of the reality of technology over the last 10 years that switching costs are real. Migrations are painful. Replatforming burns teams. Stability compounds.
That mental model has served enterprise infrastructure well for a long time. But AI (and especially AI agents) have broken it. The half-life of our agent infrastructure is now measured in months. And the strangest part is this: often by the time you’re done with a traditional architecture review, the best answer has already changed.
That’s a very unfamiliar feeling if you grew up in conventional infrastructure. For most of my career, the default assumption was that switching costs outweighed the benefits, so technology changes should be made carefully and infrequently.
With agents, we have had to adopt almost the opposite philosophy:
Another major change is probably coming soon, so architect and operate accordingly.
That isn’t just a tooling shift; it’s a cultural shift. It’s an architectural shift. And for most enterprises and technology companies that build AI systems, I suspect it’s true for them too.

The old rule: optimize for stability
In traditional enterprise infrastructure, “good judgment” usually looks like restraint.
You don’t swap databases because a new one is fashionable because you’ve spent so long optimizing and scaling your current databases. You don’t change observability vendors every year because the cost of your engineering team learning the new system will outweigh the benefits.
You choose deliberately, and then you extract value from that decision over time.
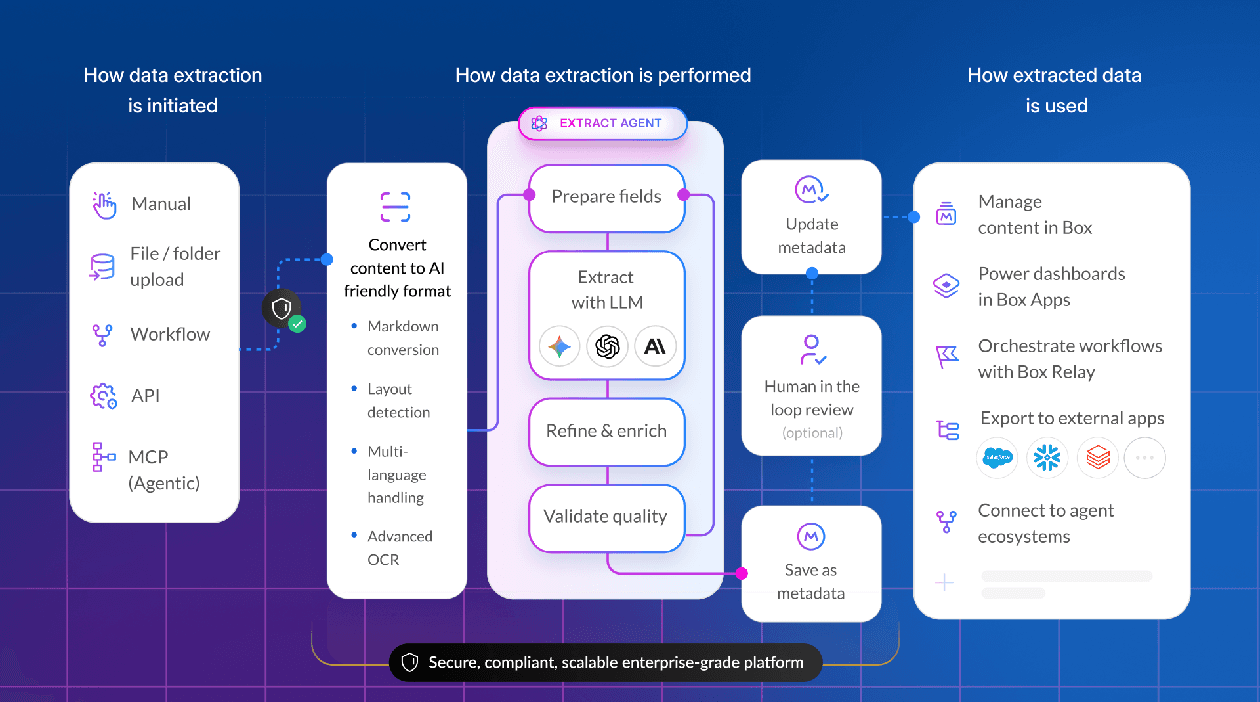
At Box, that has been the norm for years. Then we started building AI agents, which changed everything. A simplified version looks something like this:
The half-life of infrastructure decisions

That contrast still looks absurd to me, even after living through it. I’ve never seen another layer of the stack behave like this.
Why agents accelerate everything
Part of the reason is that “AI agent infrastructure” isn’t one thing. It’s a stack of moving layers that interact:
- model vendors and model versions
- agent harness and methodology
- embeddings and vector stores
- OCR and document extraction systems
- eval system and approach
- tool calling and execution environments
- security boundaries for agent actions
- agent sandbox
- observability for long-running, branching workflows
In a traditional app, if one layer improves, you may get a modest benefit.
In an agent system, a change in one layer can invalidate assumptions in all the others.
A better model changes what kind of orchestration you need.
A better tool-calling model allows evolving from rigid graphs-based planning to more autonomous planning.
A better sandbox changes whether agents can reason abstractly or write code to solve the problem directly.
A better eval framework changes what you realize was broken all along.
Each step forward doesn’t just improve the existing design;very often, it makes the old design feel like it was built for the wrong world.
Our stack changed because the workload changed
The cleanest way to explain this is to show how our agent systems evolved.
The evolution of our agent stack

What changed wasn’t just our choice of framework, but our definition of “what a good agent does.”
Every time the workload expanded, the prior architecture started to look too rigid, too shallow, or too expensive. And every time, we had the same optimistic thought:
“This is probably the last big rewrite. Our new approach is so generalized and powerful, it will last a long time.”
It never did.
The arc from 2024 to today
In 2024, a single LLM call was enough. The user asked a question, the system gathered context, the model responded. Queries averaged around 5,000 tokens and finished in seconds. It was the right approach for the early days, but it didn;t survive contact with the problem we got next.
By early 2025, users wanted more. Single-shot stopped being enough, and we moved to explicit multi-step pipelines. As an example, our data extraction agents started to do multiple orchestrated steps — OCR, extraction, validation, retry. Tokens climbed to ~15,000. Time to completion started to rise as users become comfortable waiting for higher quality answers. Multiple LLM calls became normal. Evals stopped being optional: once a system has several stages, "it looks pretty good" isn’t a quality bar. We built our own eval infrastructure. That felt like maturity, and it was — for that generation.
Mid-2025 brought graph-based orchestration: branching, looping, retries, tool invocation, state carried between nodes. A representative Box task became "deep research across my enterprise data" — something that needs iteration, conditional logic, and retrieval over files. Token usage jumped to 50,000+; latency stretched toward a minute. Graphs gave us more control, but they also exposed a new ceiling. You can only hard-code so much intelligence before you end up hard-coding around the thing you actually want: the model deciding how to solve the problem.
Late 2025 crossed that line. We moved toward autonomous agents operating in an agentic loop — give the model a broad objective and a set of tools, and let it make a plan. A request now looked like: "Make a budget spreadsheet for next year using last year's budget, headcount projections, the strategy deck, and the transcript from the budget meeting." The agent was no longer just answering; it was coordinating, deciding what to retrieve, what to produce, and when to keep going. Token usage moved into the hundreds of thousands. Query times moved into minutes.
Early 2026 is the most dramatic shift yet. Sometimes the best way to solve a complex task is not to call a fixed set of tools — it’s to write arbitrary code, execute it in an isolated environment, inspect the result, and continue. That opens the door to tasks like: Analyze 100,000 contracts, identify the riskiest ones, and produce a report, an Excel file, and a presentation. There’s no fixed workflow for that. And once you enter this world, nearly every prior assumption breaks: the harness, the security model, the observability model, the eval model, and the cost model. A single query can now cost more than a user license pays in a whole year.
This is why I say the half-life is now months. The capability frontier is moving so fast that each gain tends to pull the rest of the stack behind it.
The most important lesson: optimize for replaceability
The instinct from traditional infrastructure is to optimize a chosen architecture until it becomes durable. That instinct can work against you in agent systems; a better strategy is increasingly to optimize for replaceability.
That means a few things.
1. Assume major layers will change
Don’t architect as if your current model vendor, harness, embeddings choice, or execution pattern is permanent. It probably isn’t.
2. Separate stable contracts from unstable implementations
You need strong internal abstractions so you can change what’s behind them without rewriting everything above them. At Box, we expanded rather than replaced the representation we used to define the agents. We tweaked but didn’t replace the agentic experience. We kept our AI billing structure that balanced the capabilities included in the user cost and the ones that were charged for resourcing.
3. Evals are one of the most valuable assets
How will you really know if your new agentic stack is better than your old one? If your evals are comprehensive, represent what your users want, and provide all the data you need (quality, cost, speed, accuracy), then you’ll know the answer by the eval scores.
4. Treat observability as a core feature
When workflows become longer, more autonomous, and more expensive, you can’t improve what you can’t inspect.
5. Build organizational muscle for change
This isn’t just a code problem. Teams need to expect more churn, make decisions faster, and get comfortable revisiting prior conclusions.
That last point matters more than it sounds. In a conventional infrastructure culture, repeated change can feel like failure. It can feel like thrashing.
With AI, repeated change may simply mean you’re paying attention.
The weird part for agent builders for enterprise customers
What makes this especially strange in an enterprise setting is that all of our normal instincts still matter:
- Security is more important than ever, with new threats in addition to the traditional ones
- We need to respect all our governance and certifications
- Reliability is still absolutely critical
- We still care about cost, observability, and operational excellence.
None of that goes away. But now those requirements have to coexist with a much shorter planning horizon. That’s the real challenge: not choosing between stability and speed, but learning how to operate with both.
You need enterprise discipline with startup innovation mentality. That is a hard combination.
What I believe now
A year ago, it was still tempting to think of agent architecture as something we would converge on soon. That the early turbulence was temporary. That we would pick the right framework, the right patterns, the right model strategy — and then the stack would settle down.
I don’t believe that anymore.
I think the defining skill in this era is not selecting the final architecture. It’s building systems, abstractions, and teams that can absorb the next architectural change without starting from zero.
The hard part is no longer just “what should we build?”
It’s: how do we build so that we can change again soon?
Because if the last two years are any indication, we probably will