In the rapidly evolving landscape of enterprise AI, the ability to move beyond simple chat interactions to executing complex, multi-step workflows is becoming the new standard. Today, we are sharing insights into the performance of Anthropic’s latest model, Claude Sonnet 4.6, which is now available in Box AI Studio in Beta. We focused our evaluation on how Sonnet 4.6 handles the demands of day-to-day enterprise work compared to its predecessor, Claude Sonnet 4.5. Sonnet 4.6 outperforms Claude Sonnet 4.5 across multiple tasks, and excels at orchestration and longer horizon tasks that were previously challenging for AI agents.
Reasoning capabilities to power agents

The first pillar of our evaluation focused on the reasoning capabilities that agents require. We tested Sonnet 4.6’s ability to orchestrate, search, and perform Q&A over complex tasks across various sectors.
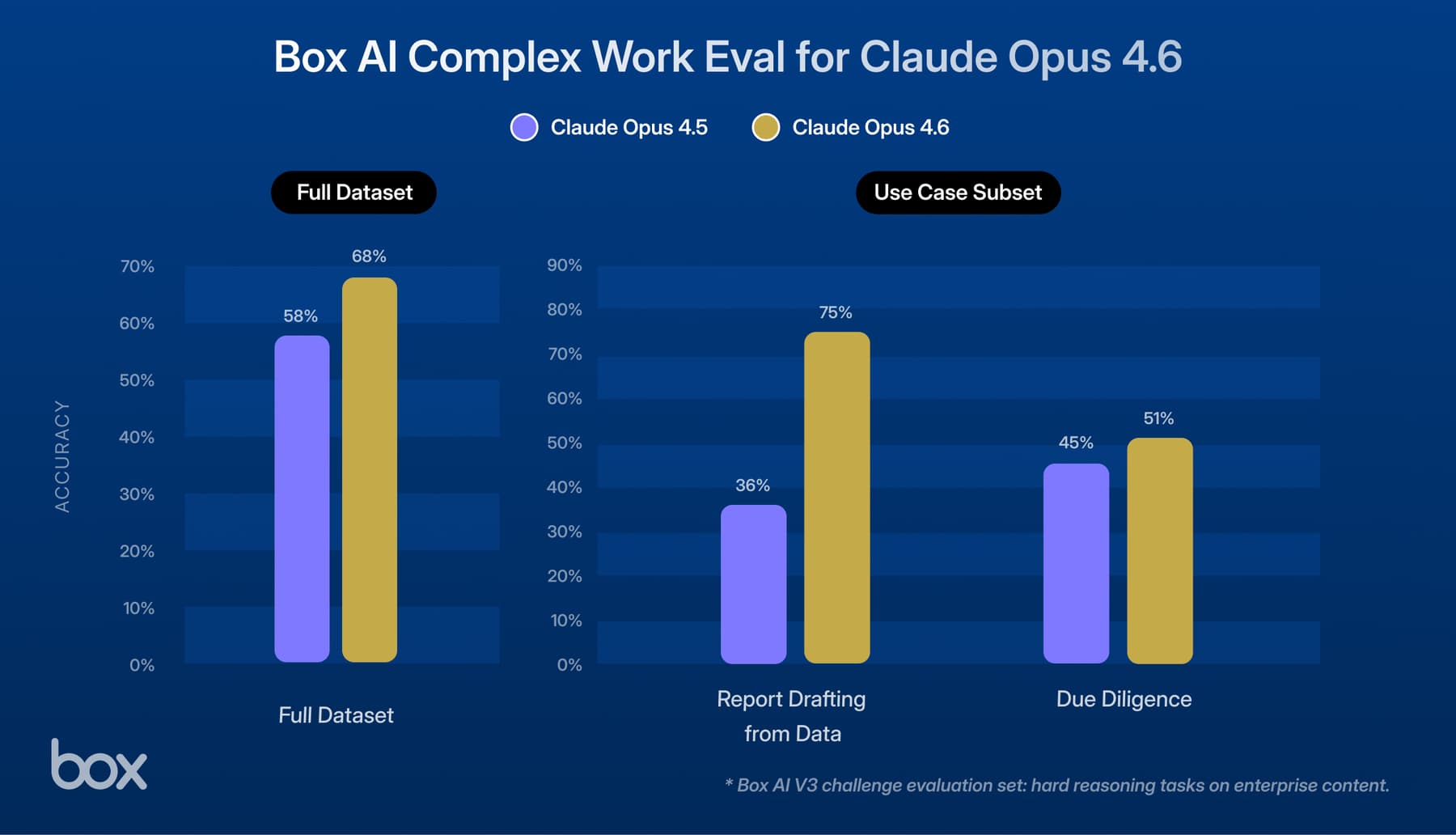
In our heavy reasoning set, Sonnet 4.6 achieved an overall accuracy score of 77%, a 15 percentage point jump over Sonnet 4.5’s 62%. This metric is crucial because it measures Sonnet 4.6’s ability to handle tasks that require deep orchestration over longer periods, rather than just quick, single-turn answers. Sonnet 4.6 also demonstrated superior accuracy across trusted sectors, with notable strength in the Public Sector (88%) and Healthcare (78%). When we look at a functional level, Sonnet 4.6 also excelled in synthesizing complex information and turning them into actionable documents, with specific improvements noted in Due Diligence and Data Analysis.
Reducing hallucinations in complex workflows

Raw numbers tell one story, but specific wins in our evaluation highlight why Sonnet 4.6 is well positioned to be the model for your day-to-day operations.
- Preventing Calculation Errors: We tested the models on a task for a retail company, analyzing multi-year sales data. The workflow required filtering articles by attributes, calculating year-over-year growth, and forecasting future costs. Sonnet 4.5 struggled with the financial interpretation, leading to cascading calculation errors. Sonnet 4.6, however, correctly computed the investment-to-cost ratios and successfully ranked the top articles by price increase.
- Ensuring Integrity in Reporting: We also tested a scenario involving a teacher piloting a targeted learning program, the model needed to summarize student outcomes to recommend a decision. Sonnet 4.5 incorrectly calculated the number of students that passed, leading to a false recommendation. Sonnet 4.6 correctly identified the number of students that passed, providing a recommendation that was aligned with the actual data.

High precision data extraction

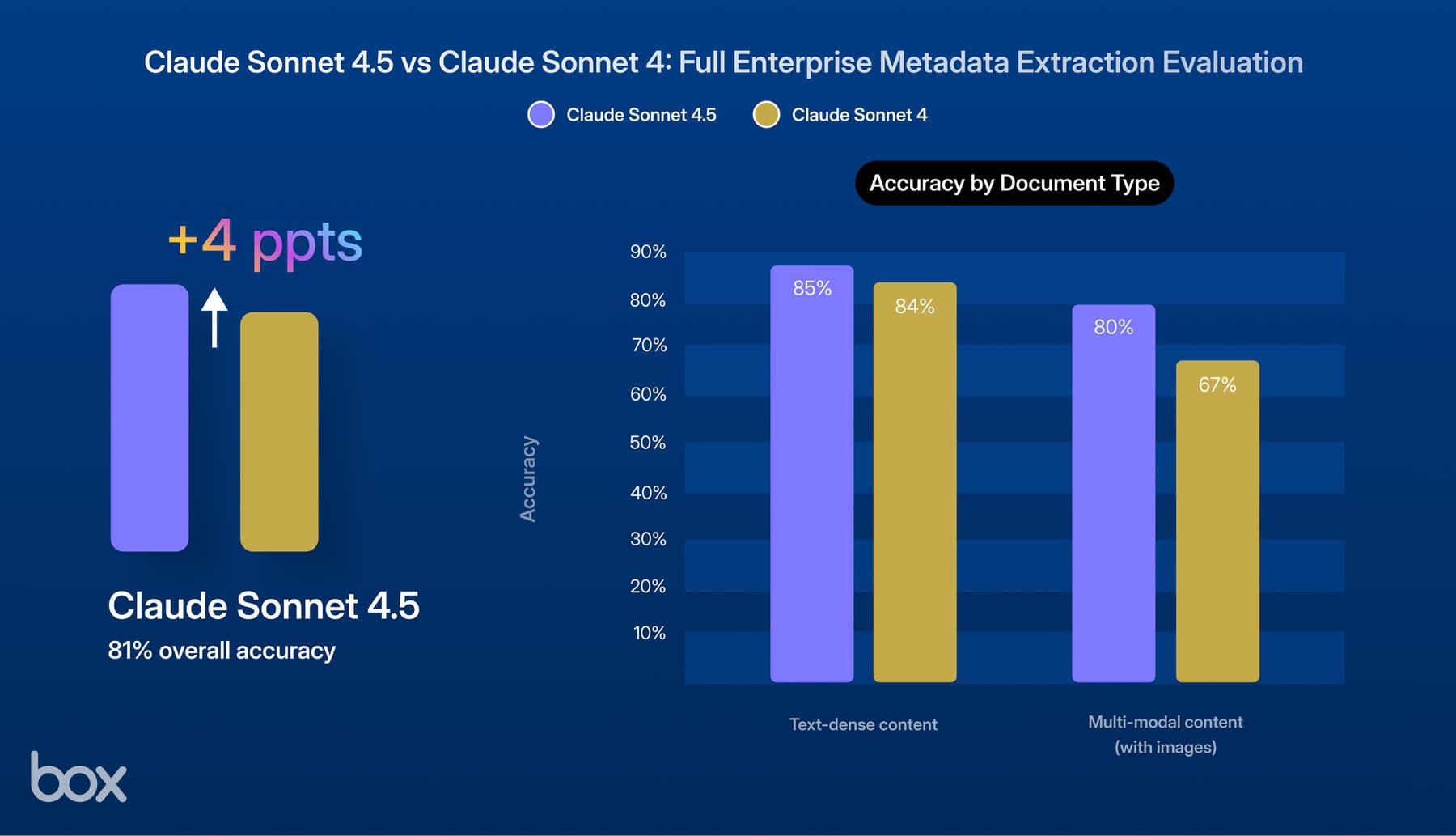
Beyond reasoning, agents must accurately extract structured data from unstructured content. In our one-shot extraction tests, Sonnet 4.6 outperformed Sonnet 4.5 in handling complex logic. Sonnet 4.6 achieved 89% accuracy on fields requiring math, compared to 62% for Sonnet 4.5. Sonnet 4.6 also maintained high performance across file types, including over 80% accuracy on PDFs and Docx files in our test set. Sonnet 4.6 also maintained strong performance on tasks requiring heavy reasoning, implying that Sonnet 4.6 did more than find data, it understood context.
Start building more reliable agents
These improvements in reasoning and extraction make Sonnet 4.6 a strong candidate for automating sophisticated workflows that require high precision. While earlier models struggled with multi-step logic, this update bridges the gap for more demanding enterprise use cases.
Sonnet 4.6 is available as a Beta model today in AI Studio and via the Box API.