This was originally published as an X article on July 2, 2026. See it here.
When Box IT began building Gizmo, our AI-powered IT support assistant, it was tempting to think the hardest part would be the assistant experience itself: getting employees to ask questions in Slack and receive useful answers. But we quickly learned that the harder problem was beneath the interface. If the knowledge behind the assistant was stale, duplicated, inconsistently structured, or missing ownership, the assistant couldn’t be trusted, no matter how polished the experience was.
This post shares how Box IT built a closed-loop knowledge system to support AI-powered IT support. The system uses Box as the foundation for knowledge intake, authoring, metadata classification, workflow governance, operational visibility, AI-assisted article creation, and continuous knowledge gap analysis. The biggest lesson was simple: AI support isn’t just a chatbot problem. It’s a knowledge systems problem.
AI support starts with knowledge quality
Like many enterprise IT teams, Box IT had years of useful support knowledge spread across multiple places: documentation repositories, historical support tickets, Slack threads, troubleshooting notes, team folders, and the institutional memory of support engineers.
For a human support engineer, that kind of knowledge sprawl is inconvenient but manageable; a support engineer can interpret an old ticket, remember missing context, ask follow-up questions, and decide whether a workaround is still safe to recommend.
An AI support assistant doesn't have that same judgment unless the knowledge system around it provides the right structure and guardrails. If two articles conflict, the assistant may retrieve the wrong one. If an article is outdated, the answer may be confidently wrong. If a document is written for engineers but shown to employees, the response may be technically correct but not useful. If ownership is unclear, stale knowledge can remain in circulation long after a process has changed.
That was the core challenge behind Gizmo: We needed to build a trusted knowledge lifecycle that could create, classify, approve, publish, retrieve, measure, and continuously improve IT support knowledge.
What Gizmo does
Gizmo is Box IT’s AI-powered support assistant for employee IT questions. Employees ask questions through Slack, and Gizmo uses approved IT knowledge to generate responses or guide employees toward the right support path. At a high level, Gizmo combines a Slack-based support experience, a conversational AI layer, and a governed Box knowledge system.
The flow looks like this:
- An employee asks an IT support question.
- Gizmo interprets the intent of the question.
- Gizmo retrieves relevant content from a governed Box-based knowledge repository.
- A response is generated from approved knowledge content.
- If the question can’t be answered safely or completely, the employee is guided toward the right escalation path.
That flow sounds straightforward, but it only works when the retrieval layer is grounded in content that’s accurate, current, scoped to the right audience, and eligible for employee-facing use.
Gizmo doesn’t retrieve from a loose collection of unmanaged documents. The assistant accesses knowledge through Box APIs, which provide access to governed content that has passed through the publication lifecycle. Metadata, access level, and article status help determine which content is eligible for retrieval.
One important design choice was separating the assistant experience from the knowledge foundation. The assistant layer can evolve over time, but the durable part of the architecture is the governed Box knowledge system underneath it. That separation allows us to improve the employee experience without rebuilding the content lifecycle each time the front-end experience changes.
Designing a closed-loop knowledge lifecycle
We designed the system as a lifecycle rather than a static knowledge base. The goal was to create a loop where knowledge could move through clear stages:
- Intake
- Drafting and authoring
- AI-assisted article improvement
- Metadata classification
- Quality review
- Workflow governance
- Publication
- Retrieval by Gizmo
- Gap analysis and continuous improvement
The closed-loop part matters. Once Gizmo was live, real support demand became a signal. Unresolved questions, repeated topics, weak answers, and missing articles could all feed back into the knowledge process. Instead of treating knowledge management as a one-time documentation push, we designed the system to keep improving based on what employees actually asked for.
This changed how we thought about the project. Gizmo was the front door, but the knowledge system became the foundation.
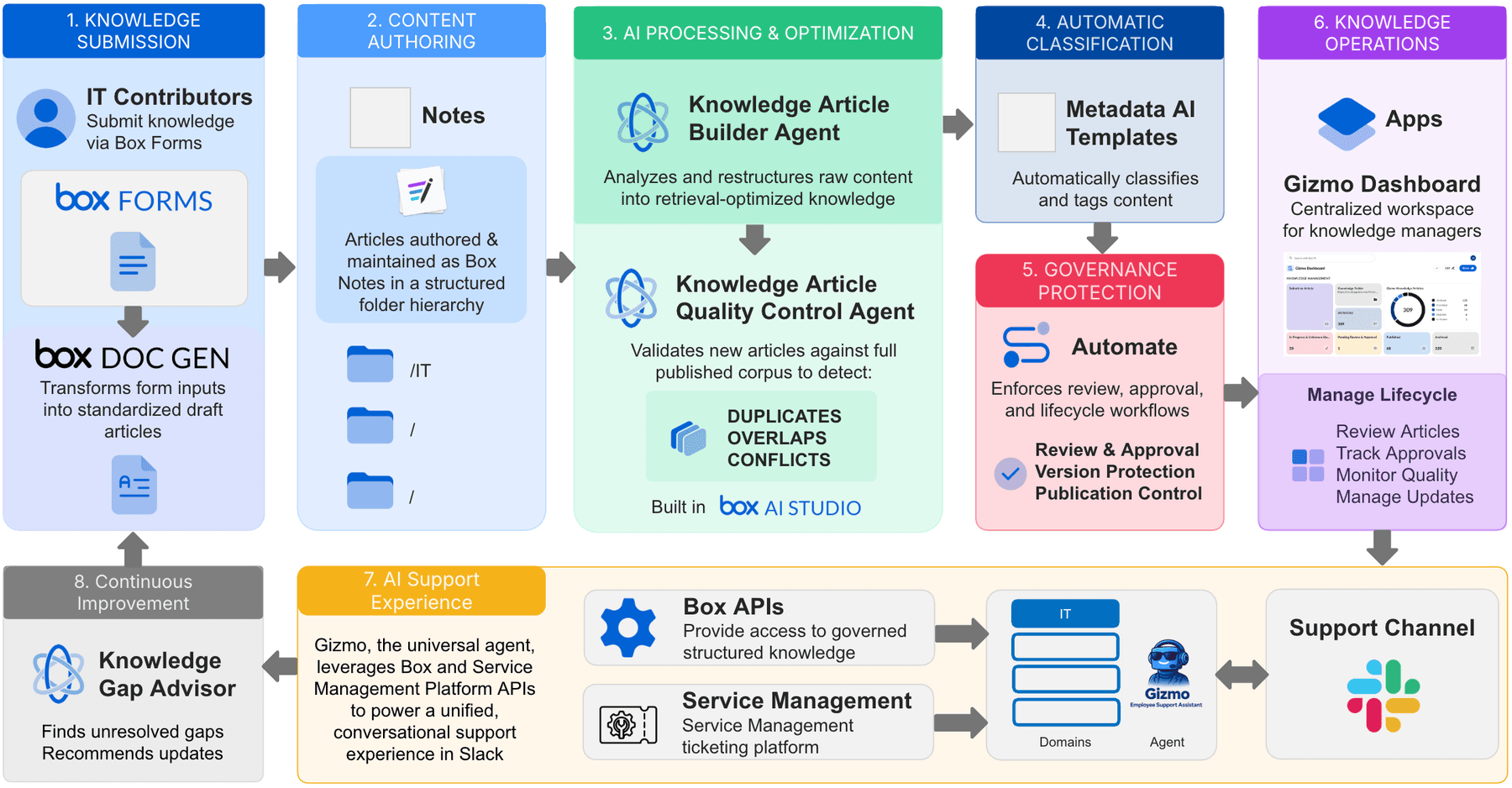
Diagram: Gizmo Architecture Powered by Box
The architecture diagram for this system shows the lifecycle as a loop:
- IT contributors submit knowledge through Box Forms
- Box DocGen helps create standardized drafts
- Articles are authored in Box Notes
- Box AI Studio agents help optimize and validate the content
- Metadata classification supports retrieval and governance
- Box Automate enforces review and publication controls
- Box Apps provides operational visibility.
- Gizmo then accesses governed knowledge through Box APIs to support employees in Slack.
- Knowledge Gap Advisor completes the loop by analyzing unresolved support demand and feeding recommended updates back into the knowledge submission process.
Turning raw support knowledge into AI-ready articles
One of the biggest challenges was that useful support knowledge rarely starts in a clean article format.
Instead, it often starts as a ticket thread, an engineer’s troubleshooting note, an incident summary, or a Slack conversation where several people contributed partial context. That information is valuable, but it’s not immediately useful for AI retrieval.
For example, consider a common enterprise IT scenario: an employee has trouble connecting to VPN from a Mac. The raw support content might include:
- A short employee description of the issue
- Several back-and-forth troubleshooting comments
- Device-specific details
- A few steps that worked
- A few steps that didn’t work
- A final resolution buried at the bottom of the ticket
- Internal notes that shouldn’t be shown directly to employees
A human support engineer can read that and understand the path to resolution. But for an AI support assistant, that raw thread needs to become something more structured.
Using Box AI Studio, we created an AI-assisted knowledge article builder pattern that transforms raw support content into a cleaner draft. The agent identifies the primary employee-facing question, removes noise, separates unrelated issues, and restructures the content into a more retrieval-friendly article.
The finished output might look like this:
Title: How do I fix VPN connection issues on my Mac?
Overview: Use this article if VPN won’t connect, disconnects repeatedly, or shows a connection error on macOS.
Symptoms: VPN fails to connect, disconnects after sign-in, or shows an error after authentication.
Steps to try: Restart the VPN client, verify network connectivity, confirm the device is up to date, and retry authentication.
When to contact IT: Contact IT if the issue continues after the basic troubleshooting steps or if the device shows an error that indicates account, device compliance, or access policy review is required.
Owner: Support Engineering
Audience: All Employees
Access Level: Internal
The important point is that AI doesn’t replace human ownership. The AI-assisted builder helps create a better first draft, but a human reviewer still owns accuracy, policy alignment, and publication approval.
That distinction became one of our operating principles: AI can accelerate knowledge creation, but humans remain accountable for trusted knowledge.
Metadata as the control plane
Metadata became one of the most important parts of the system.
At first glance, metadata can look like administrative overhead. In practice, it became the control plane for the knowledge lifecycle. It helped determine ownership and review state, visibility, retrieval eligibility, dashboard reporting, and whether an article was appropriate for employee-facing AI responses.
A simplified version of our metadata model looks like this:
One design choice was especially important: retrieval eligibility shouldn’t be a casual label someone applies manually. It should be derived from lifecycle state and access level.
For example:
- Published + Internal = eligible for employee-facing AI retrieval
- Published + Restricted IT = eligible only for internal IT use
- Draft, In Review, or Archived = not eligible for employee-facing retrieval
This helped us connect human governance to AI behavior. Metadata was no longer just a way to organize content; it became the bridge between knowledge management, workflow automation, and retrieval quality.
We also used AI-assisted metadata classification to reduce the burden on contributors. Rather than expecting every author to classify content perfectly, AI can help suggest or populate fields based on the article body. Humans can still review and correct those values, but the starting point is more consistent.
The lesson for us was clear: if the metadata schema is too shallow, the AI system lacks useful context. If the schema is too complex, contributors won’t maintain it. The right design has to serve both humans and machines.
Box Automate as the governance layer
Governance only works at scale when it’s part of the workflow.
We used Box Automate to enforce key parts of the knowledge lifecycle, including review routing, approval steps, publication controls, and change monitoring. The goal was to prevent unreviewed or stale content from quietly becoming part of the AI retrieval experience.
One of the most important patterns was published article change review.
A published article isn’t static. Systems change, support processes evolve, policies get updated, and employees discover new edge cases. If a published article changes silently, the AI assistant may continue retrieving it without anyone validating whether the new guidance is still correct.
To reduce that risk, we treated changes to published knowledge as lifecycle events, not just document edits.
A simplified workflow looks like this:
- A published article is edited.
- Box Automate detects the change.
- The article owner or knowledge manager is notified.
- A review task is created.
- The change is validated for accuracy and employee readiness.
- If needed, the article moves through re-review before remaining eligible for AI retrieval.
We also used simpler workflows for new article intake:
- A contributor submits a new article or draft.
- Required metadata is checked.
- The article is routed to the right reviewer.
- The article cannot move to published status until review is complete.
- Once approved, it becomes eligible for the appropriate retrieval experience.
The main lesson was that governance can’t depend on people remembering every step. If review, approval, and publication controls aren’t built into the lifecycle, the knowledge base will decay over time.
Quality control before publication
As the knowledge base grew, another challenge emerged: duplicate and overlapping articles.
Two teams might write about the same system from different perspectives. One article might explain how to request access, while another explains how to troubleshoot access. That distinction can be useful, but if both articles answer the same employee question with different steps, the assistant may retrieve inconsistent guidance.
To address this, we built a quality control pattern using Box AI Studio and Box Hubs.
The idea was to validate new or updated articles against the existing published corpus before publication. The quality control agent checks for issues such as:
- Duplicate articles that answer the same question
- Overlapping content that should be consolidated
- Conflicting guidance
- Vague or unclear titles
- Articles that are too broad for reliable retrieval
- Content that should be scoped differently by audience or access level
Box Hubs provides a curated reference layer of published knowledge. The quality control agent can compare a draft against that governed corpus and provide recommendations to the knowledge manager.
This is another place where AI helps the process without owning the final decision. The agent can surface likely duplication or conflict, but a human reviewer decides whether to revise, merge, reject, or approve the article.
Knowledge Gap Advisor closes the loop
The most important improvement to the system was adding a way to detect what was missing.
A knowledge base can look healthy because it has lots of content, but volume doesn’t equal coverage. What matters is whether the content answers the questions employees are actually asking.
That’s why we built Knowledge Gap Advisor.
Every seven days, Knowledge Gap Advisor receives an automated export of unresolved requests, resolved requests that still resulted in a support ticket, and requests with negative feedback. That export triggers Box Automate, which launches the analysis automatically. The agent analyzes the export, compares the request topics against the existing published knowledge base, and identifies where the knowledge system appears to be missing, weak, outdated, or insufficiently retrievable. It also groups similar requests into recurring support drivers so the team can focus on patterns instead of one-off examples.
The output isn’t an automatic publishing action. It’s a recommendation set for the knowledge team.
Knowledge Gap Advisor helps identify:
- Missing articles
- Weak or incomplete articles
- Duplicate or overlapping content
- Topics where existing knowledge didn’t fully resolve the issue
- Topics that should route to support instead of being answered directly
- Articles needing review, ownership clarification, or updates
The team then reviews the recommendations, decides which findings are valid, drafts new articles or updates existing ones, and sends those changes back through the standard metadata, review, and Box Automate governance workflow.
That weekly cycle is what makes the system closed-loop. Real support demand becomes input for improving the knowledge base. The knowledge base improves the assistant. The assistant reduces friction for employees. New unresolved questions reveal the next set of improvements.
Today, the system manages hundreds of IT knowledge articles and uses this weekly gap-analysis cycle to turn unresolved support demand into targeted knowledge improvements.
What was hardest
At the beginning, one of the hardest parts was recognizing the full potential of the platform we already had.
Many of the workflows we wanted, including knowledge intake, article drafting, metadata classification, quality review, approval routing, and gap analysis, were things we’d talked about before. The challenge was that they had historically required too much manual effort to sustain; someone had to collect the request, format the article, classify the content, route it for review, track status, identify stale knowledge, and follow up with owners. Each step was reasonable on its own, but together they created too much operational drag.
That changed as we started using Box AI Studio, Box Apps, Box Hubs, Box Metadata, and Box Automate together. Workflows that previously felt too manual to operationalize became surprisingly accessible to configure. That shifted our attention away from simply asking, “Can we automate this?” and toward a more important question: “What experience are we trying to create for employees and support teams?”
That was an important turning point. Once the backend workflow became easier to assemble, the harder problem became designing knowledge for both humans and AI.
A good employee-facing article needs to be simple, readable, and actionable. A good retrieval article needs to be focused, consistently structured, and specific enough to match the right question. A good governed article needs ownership, lifecycle state, access controls, and review cadence.
Those needs sometimes compete.
If an article is too broad, it may be useful for browsing but weak for retrieval. If it’s too narrow, it may retrieve well but create too much content to maintain. If metadata is too flexible, it becomes inconsistent. If metadata is too rigid, contributors work around it. If governance is too light, trust suffers. If governance is too heavy, teams avoid contributing.
We had to iterate on the balance.
Another hard lesson was that knowledge gaps aren’t always obvious from inside the team. Engineers may assume an answer is documented because they know where to find it, or because the answer exists in an old ticket. But from the employee’s perspective, and from the assistant’s retrieval perspective, that knowledge may effectively be missing.
That is why usage signals and unresolved support patterns became so important. They helped us see the knowledge base from the outside in.
Lessons learned
Several lessons have shaped how we think about AI-powered support.
Knowledge quality determines AI quality. The assistant is only as reliable as the content it can retrieve. Better prompts can’t fully compensate for stale, conflicting, or poorly structured knowledge.
Metadata is part of the architecture. Metadata isn’t just classification. It controls ownership, visibility, lifecycle state, retrieval eligibility, and operational reporting.
Automation is required for governance to scale. Review and approval processes need to be built into the workflow. Manual reminders aren’t enough to keep a production knowledge system healthy.
AI should improve knowledge, not just consume it. AI can help draft articles, identify duplicates, classify content, and surface gaps. That makes the knowledge system itself better over time.
Human ownership remains essential. AI can recommend and accelerate, but humans must own accuracy, policy alignment, and publication decisions.
The operating model matters as much as the technology. A reliable AI support system needs clear owners, review expectations, escalation paths, and continuous improvement practices.
What’s next
Our initial implementation focused on IT support, where we could prove the closed-loop model against a real production support use case. Over time, we plan to extend the same pattern to other employee service domains, including People and Workplace Services.
The next challenge isn’t simply adding more agents. Each domain needs the same foundation: clear ownership, trusted knowledge, metadata standards, governance workflows, and a feedback loop for continuous improvement. Scaling the model successfully means scaling the operating discipline behind it, not just the assistant experience.
That’s where the broader opportunity lies. As more teams explore AI-powered support, the strongest pattern will be the system that can keep knowledge accurate, governed, measurable, and continuously improving.
Final thoughts
Gizmo started as a way to help employees get faster answers to IT questions. But the lasting lesson was broader.
Reliable AI support depends on the knowledge system underneath it.
When knowledge is scattered, stale, or ungoverned, AI becomes difficult to trust. When knowledge is structured, reviewed, metadata-rich, and continuously improved, AI can become a reliable front door to support.
That’s the pattern we’re continuing to build at Box: not just an assistant, but a closed-loop knowledge system that helps support teams learn from real demand and improve over time.
About the author
Jason Bergado is Senior Director of IT End User Services at Box, where he leads teams focused on employee support, service engineering, unified communications & collaboration, and AI-enabled service experiences.