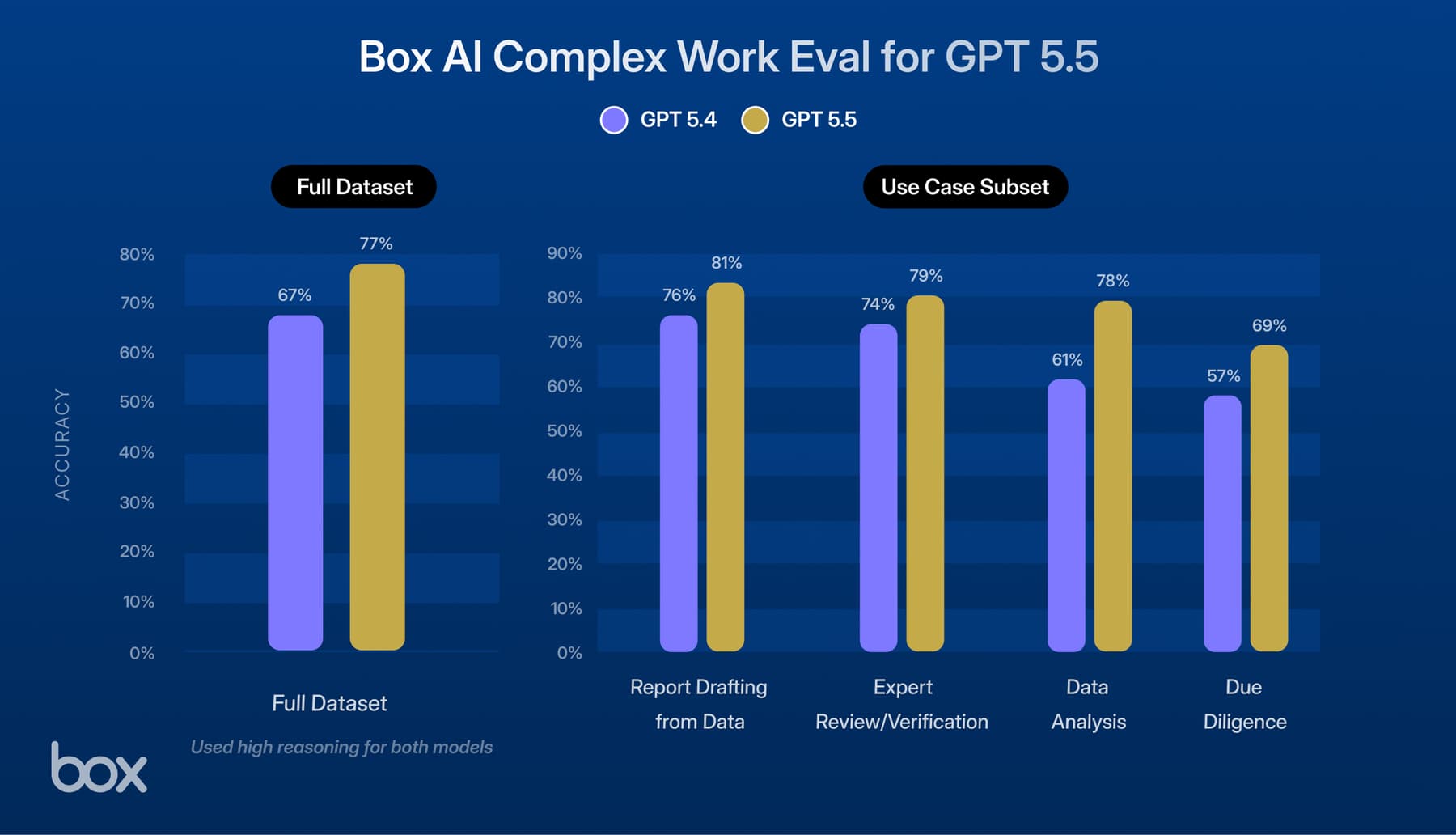
Claude Opus 4.8, Anthropic’s newest model, surpasses Opus 4.7 performance and shows meaningful gains on report drafting, financial analysis, and public sector tasks in our enterprise evaluation suite.
At Box, we evaluate all frontier models against the same rigorous framework: a suite of enterprise tasks drawn from real-world use cases across industries. Each task requires the agent to retrieve content from documents, extract information, and produce structured outputs — the same workflows our customers run every day.

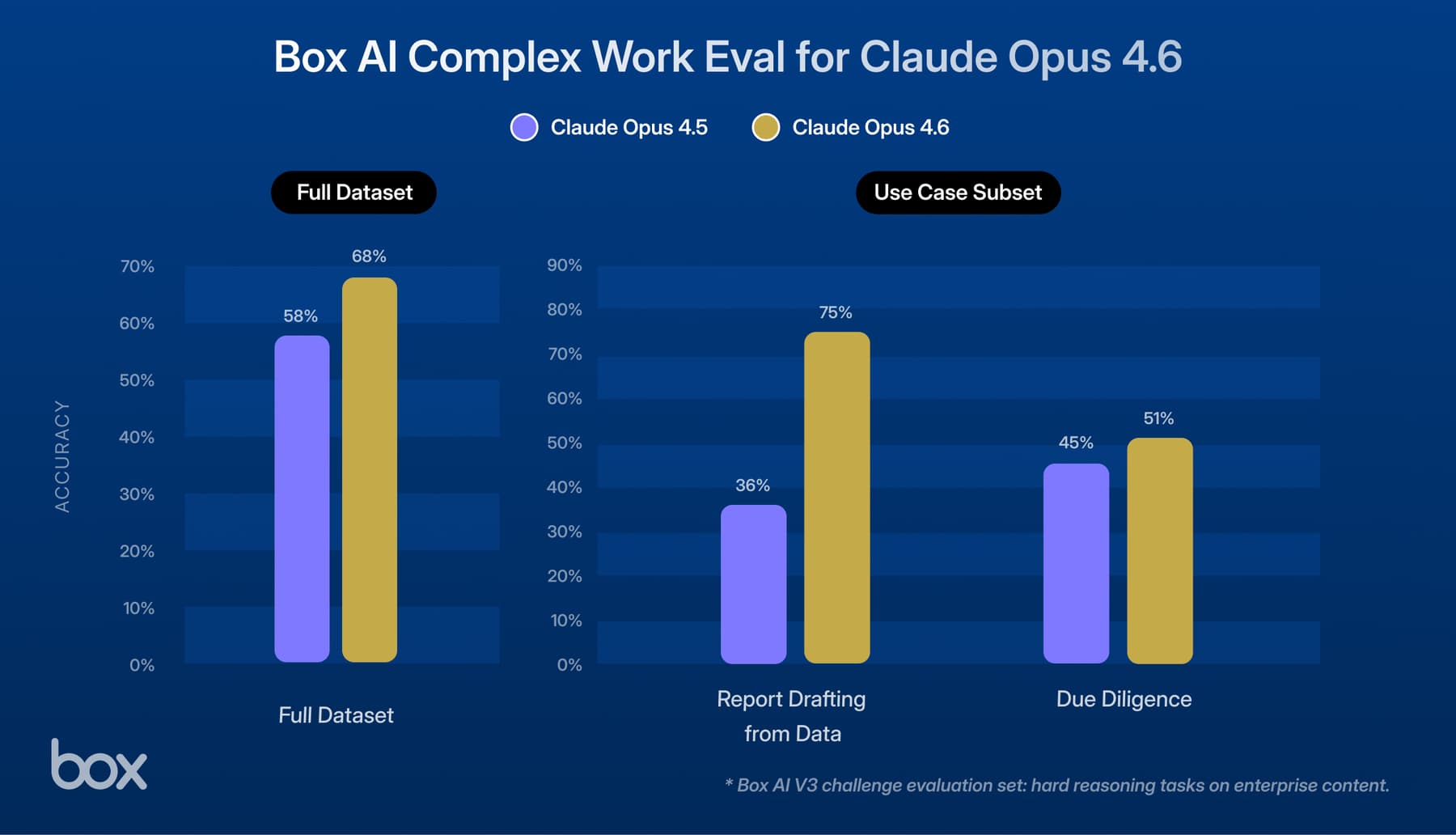
We tested Opus 4.8 head to head against Opus 4.7 on this evaluation, running five independent trials per task to ensure statistical reliability. Both models ran on the same agent framework, with the same tools and prompts, isolating model capability as the only variable.

Where Opus 4.8 pulls ahead
Opus 4.8 demonstrates its strongest gains on report drafting and data analysis tasks:
- Report drafting: Opus 4.8 outperforms on a majority of report drafting tasks, producing more complete and accurate analytical reports. On an industrial goods reporting task, it scored 87% vs 77% for Opus 4.7; on a consumer products launch evaluation, 90% vs 84%.
- Review and verification: On a legal NDA review task requiring verification of contract terms against compliance criteria, Opus 4.8 catches more relevant clauses and flags more potential issues, with near-perfect consistency across all trials.
- Financial data analysis: On a corporate lending analysis task comparing syndicated vs bilateral loan structures, Opus 4.8 extracts more accurate financial metrics from source documents, leading by nearly 8 percentage points.

Performance by Industry
Taken together, these results point to a model that is meaningfully more reliable when the stakes of getting it wrong are high. The gains are concentrated in structured, high-judgment work: contracts, financial documents, and analytical reports where missed details or inaccurate extractions carry real consequences.
Opus 4.8 shows particular strength in public sector and financial services tasks:
- Public sector (+5.8 percentage points): Opus 4.8 outperforms on a math intervention reporting task and a library grant data analysis task, achieving near-perfect accuracy on the latter
- Financial services (+1.7 percentage points): Opus 4.8 outperforms on corporate lending analysis and financial report synthesis tasks
Opus 4.8 performs best where tasks demand precision over prose. Both sectors represent exactly the kind of high-accountability use cases where incremental accuracy improvements translate directly into reduced review burden and greater confidence in model outputs.
Impact across enterprise use cases
Three examples illustrate how Opus 4.8 delivers better outcomes:
- Consumer products launch evaluation: On a task requiring assessment of a product launch across multiple performance dimensions, Opus 4.8 captured evaluation criteria that Opus 4.7 missed — producing a more thorough analysis that covered all required factors rather than just the most obvious ones.
- Legal NDA review: On a task verifying NDA terms against compliance criteria, Opus 4.8 identified more relevant clauses and flagged potential issues that Opus 4.7 missed. Its outputs were also highly predictable — producing nearly identical quality across independent runs.
- Public sector grant analysis: When analyzing library grant documentation against eligibility criteria, Opus 4.8 correctly extracted and validated nearly all required data points, catching specific eligibility details that Opus 4.7 overlooked or misinterpreted.
In each case, the gap between models came down to whether the AI noticed what it was supposed to notice — a missed evaluation dimension, an unexamined contract clause, an overlooked eligibility requirement. These are exactly the errors that are hardest to catch in human review, because reviewers often use the model’s output as their starting point.
Opus 4.8’s higher coverage and consistency means less risk of blind spots becoming invisible gaps in the final work product.
Get started today
Claude Opus 4.8 will be available for Box AI customers soon.